Comprendre la virtualisation sous Linux
Leçon d'histoire de la virtualisation sous Linux

Voici la traduction en français du chapitre 1 et une partie du chapitre 2 du livre "Mastering KVM Second Edition" (2020) des éditions Packt qui est une leçon d'histoire sur la virtualisation sous Linux.
Chapitre 1 : Comprendre la virtualisation sous Linux
La virtualisation est la technologie qui a amorcé un grand virage technologique vers la consolidation informatique, qui permet une utilisation plus efficace des ressources, et le cloud, qui est une version plus intégrée, automatisée et orchestrée de la virtualisation, axée non seulement sur les machines virtuelles mais aussi sur des services supplémentaires. Ce livre compte au total 16 chapitres, tous alignés pour couvrir tous les aspects importants de la virtualisation KVM (Kernel-based Virtual Machine). Nous commencerons par les sujets de base de KVM tels que l'histoire des concepts de virtualisation et la virtualisation de Linux, puis nous nous pencherons sur les sujets avancés de KVM tels que l'automatisation, l'orchestration, la mise en réseau virtuelle, le stockage et le dépannage. Ce chapitre vous donnera un aperçu des technologies dominantes dans la virtualisation Linux et de leurs avantages par rapport aux autres.
Dans ce chapitre, nous couvrirons les sujets suivants :
- La virtualisation Linux et ses concepts de base
- Types de virtualisation
- Hyperviseur/VMM
- Projets de virtualisation open source
- Ce que la virtualisation Linux vous offre dans le cloud
La virtualisation de Linux et comment tout a commencé
La virtualisation est un concept qui crée des ressources virtualisées et les fait correspondre à des ressources physiques. Ce processus peut être réalisé à l'aide de fonctionnalités matérielles spécifiques (partitionnement, via une sorte de contrôleur de partition) ou de fonctionnalités logicielles (hyperviseur). Ainsi, à titre d'exemple, si vous disposez d'un serveur physique basé sur un PC avec 16 cœurs exécutant un hyperviseur, vous pouvez facilement créer une ou plusieurs machines virtuelles avec deux cœurs chacune et les démarrer. Les limites concernant le nombre de machines virtuelles que vous pouvez démarrer dépendent du fournisseur. Par exemple, si vous exécutez Red Hat Enterprise Virtualization v4.x (un hyperviseur bare-metal basé sur KVM), vous pouvez utiliser jusqu'à 768 cœurs ou threads de CPU logiques (vous trouverez plus d'informations à ce sujet sur https://access.redhat.com/articles/906543). Quoi qu'il en soit, l'hyperviseur sera l'interlocuteur privilégié qui essaiera de gérer cela aussi efficacement que possible, afin que toutes les charges de travail de la machine virtuelle passent le plus de temps possible sur le CPU.
Je me souviens très bien avoir écrit mon premier article sur la virtualisation en 2004. AMD venait de sortir ses premiers processeurs 64 bits grand public en 2003 (Athlon 64, Opteron) et cela m'a un peu déstabilisé. Intel hésitait encore un peu à lancer un processeur 64 bits - l'absence d'un système d'exploitation Microsoft Windows 64 bits y était peut-être aussi pour quelque chose. Linux était déjà sorti avec un support 64 bits, mais c'était l'aube de beaucoup de nouvelles choses à venir sur le marché des PC. La virtualisation en tant que telle n'était pas une idée révolutionnaire puisque d'autres entreprises disposaient déjà de produits non-x86 capables de faire de la virtualisation depuis des décennies (par exemple, IBM CP-40 et son S/360-40, depuis 1967). Mais c'était assurément une idée nouvelle pour le marché des PC, qui se trouvait dans une phase bizarre où beaucoup de choses se passaient en même temps. Le passage à des processeurs 64 bits avec l'apparition sur le marché de processeurs multicœurs, puis le passage de DDR1 à DDR2, et enfin de PCI/ISA/AGP à PCI Express, comme vous pouvez l'imaginer, a été une période difficile.
Plus précisément, je me souviens avoir pensé aux possibilités - à quel point il serait cool d'exécuter un système d'exploitation, puis deux autres systèmes d'exploitation par-dessus. Travaillant dans le secteur de l'édition, vous pouvez imaginer les nombreux avantages que cela offrirait au flux de travail de chacun, et je me souviens avoir été vraiment enthousiasmé par cette idée.
Une quinzaine d'années de développement plus tard, nous avons maintenant un marché concurrentiel en termes de solutions de virtualisation - Red Hat avec KVM, Microsoft avec Hyper-V, VMware avec ESXi, Oracle avec Oracle VM, et Google et d'autres acteurs clés qui se disputent les utilisateurs et la domination du marché. Cela a conduit au développement de diverses solutions de cloud telles que EC2, AWS, Office 365, Azure, vCloud Director et vRealize Automation pour différents types de services de cloud. Dans l'ensemble, ces 15 années ont été très productives pour l'informatique, n'est-ce pas ?
Mais, pour revenir à octobre 2003, avec tous les changements qui se sont produits dans l'industrie informatique, il y en a un qui a été vraiment important pour ce livre et la virtualisation pour Linux en général : l'introduction du premier hyperviseur open source pour l'architecture x86, appelé Xen. Il prend en charge diverses architectures de processeurs (Itanium, x86, x86_64 et ARM) et peut exécuter divers systèmes d'exploitation (Windows, Linux, Solaris et certaines versions de BSD). Il est toujours en activité en tant que solution de virtualisation de choix pour certains fournisseurs, tels que Citrix (XenServer) et Oracle (Oracle VM). Nous entrerons dans les détails techniques de Xen un peu plus tard dans ce chapitre.
Le plus grand acteur du marché de l'open source, Red Hat, a inclus la virtualisation Xen dans les versions initiales de son Red Hat Enterprise Linux 5, sorti en 2007. Mais Xen et Red Hat n'étaient pas exactement compatibles et, bien que Red Hat ait livré Xen avec sa distribution Red Hat Enterprise Linux 5, Red Hat est passé à KVM dans Red Hat Enterprise Linux 6 en 2010, ce qui était - à l'époque - une décision très risquée. En fait, tout le processus de migration de Xen vers KVM a commencé dans la version précédente, avec les versions 5.3/5.4, toutes deux sorties en 2009. Pour replacer les choses dans leur contexte, KVM était un projet assez jeune à l'époque, âgé de quelques années seulement. Mais il y avait plus que quelques raisons valables pour lesquelles cela s'est produit, allant de Xen n'est pas dans le noyau principal, KVM l'est, à des raisons politiques (Red Hat voulait plus d'influence sur le développement de Xen, et cette influence s'estompait avec le temps).
Techniquement parlant, KVM utilise une approche différente et modulaire qui transforme les noyaux Linux en hyperviseurs entièrement fonctionnels pour les architectures de CPU prises en charge. Lorsque nous parlons d'architectures de CPU prises en charge, nous parlons de la condition de base pour la virtualisation KVM - les CPU doivent prendre en charge les extensions de virtualisation matérielle, connues sous le nom de AMD-V ou Intel VT. Pour rendre les choses un peu plus faciles, disons simplement que vous allez devoir faire de gros efforts pour trouver un CPU moderne qui ne prend pas en charge ces extensions. Par exemple, si vous utilisez un processeur Intel sur votre serveur ou votre PC de bureau, les premiers processeurs qui ont pris en charge les extensions de virtualisation matérielle remontent à 2006 (Xeon LV) et 2008 (Core i7 920). Encore une fois, nous entrerons dans les détails techniques de KVM et nous comparerons KVM et Xen un peu plus tard dans ce chapitre et dans le suivant.
Types de virtualisation
Il existe différents types de solutions de virtualisation, qui visent tous des cas d'utilisation différents et dépendent du fait que l'on virtualise un élément différent de la pile matérielle ou logicielle, c'est-à-dire ce que l'on virtualise. Il convient également de noter qu'il existe différents types de virtualisation en fonction de la manière dont vous virtualisez - par partitionnement, virtualisation complète, paravirtualisation, virtualisation hybride ou virtualisation basée sur des conteneurs.
Commençons par les cinq différents types de virtualisation dans l'informatique d'aujourd'hui, en fonction de ce que vous virtualisez :
- La virtualisation des postes de travail (Virtual Desktop Infrastructuree (VDI)) : Elle est utilisée par de nombreuses entreprises et offre d'énormes avantages dans de nombreux scénarios, car les utilisateurs ne dépendent pas d'un appareil spécifique pour accéder à leur système de bureau. Ils peuvent se connecter à partir d'un téléphone mobile, d'une tablette ou d'un ordinateur, et ils peuvent généralement se connecter à leur bureau virtualisé de n'importe où, comme s'ils étaient assis sur leur lieu de travail et utilisaient un ordinateur matériel. Parmi les avantages, citons une gestion et une surveillance centralisées plus faciles, des flux de travail de mise à jour beaucoup plus simplifiés (vous pouvez mettre à jour l'image de base de centaines de machines virtuelles dans une solution VDI et la relier à des centaines de machines virtuelles pendant les heures de maintenance), des processus de déploiement simplifiés (plus d'installations physiques sur les postes de travail, les stations de travail ou les ordinateurs portables, ainsi que la possibilité de gérer les applications de manière centralisée) et une gestion plus facile des options liées à la conformité et à la sécurité.
- La virtualisation des serveurs : Elle est utilisée par une grande majorité des entreprises informatiques aujourd'hui. Elle permet une bonne consolidation des machines virtuelles de serveur par rapport aux serveurs physiques, tout en offrant de nombreux autres avantages opérationnels par rapport aux serveurs physiques ordinaires - plus facile à sauvegarder, plus efficace sur le plan énergétique, plus libre en termes de déplacement des charges de travail d'un serveur à l'autre, etc.
- La virtualisation des applications : Elle est généralement mise en œuvre à l'aide d'une technologie de streaming/protocole à distance telle que Microsoft App-V, ou d'une solution permettant de regrouper les applications dans des volumes qui peuvent être montés sur la machine virtuelle et profilés pour des paramètres et des options de livraison cohérents, tels que VMware App Volumes.
- La virtualisation du réseau (et un concept plus large, basé sur le cloud, appelé Software-Defined Networking (SDN)) : Il s'agit d'une technologie qui crée des réseaux virtuels indépendants des dispositifs de mise en réseau physiques, tels que les commutateurs. À une échelle beaucoup plus grande, le SDN est une extension de l'idée de virtualisation du réseau qui peut s'étendre à plusieurs sites, emplacements ou centres de données. En ce qui concerne le concept de SDN, la configuration complète du réseau se fait par logiciel, sans que vous ayez nécessairement besoin d'une configuration de réseau physique spécifique. Le plus grand avantage de la virtualisation de réseau est la facilité avec laquelle vous pouvez gérer des réseaux complexes couvrant plusieurs sites sans avoir à effectuer une reconfiguration massive du réseau physique pour tous les périphériques physiques sur le chemin des données du réseau. Ce concept sera expliqué au Chapitre 4, libvirt Networking, et au Chapitre 12, Scaling Out KVM with OpenStack.
- La virtualisation du stockage (et un concept plus récent, le stockage défini par logiciel (SDS)) : Il s'agit d'une technologie qui crée des périphériques de stockage virtuels à partir de périphériques de stockage physiques mis en commun, que nous pouvons gérer de manière centralisée comme un seul périphérique de stockage. Cela signifie que nous créons une sorte de couche d'abstraction qui va isoler la fonctionnalité interne des dispositifs de stockage des ordinateurs, des applications et d'autres types de ressources. Le SDS, en tant qu'extension de cela, découple la pile logicielle de stockage du matériel sur lequel elle s'exécute en abstrayant les plans de contrôle et de gestion du matériel sous-jacent, et en offrant différents types de ressources de stockage aux machines virtuelles et aux applications (ressources en blocs, fichiers et objets).
Si vous examinez ces solutions de virtualisation et que vous les faites évoluer massivement (indice : le cloud), c'est à ce moment-là que vous réalisez que vous allez avoir besoin de divers outils et solutions pour gérer efficacement l'infrastructure en constante expansion, d'où le développement de divers outils d'automatisation et d'orchestration. Certains de ces outils seront abordés plus loin dans cet ouvrage, comme Ansible au chapitre 11, Ansible for Orchestration and Automation. Pour l'instant, disons simplement que vous ne pouvez pas gérer un environnement contenant des milliers de machines virtuelles en vous appuyant uniquement sur des utilitaires standard (scripts, commandes et même outils GUI). Vous aurez certainement besoin d'une approche plus programmatique, pilotée par API et étroitement intégrée à la solution de virtualisation, d'où le développement d'OpenStack, d'OpenShift, d'Ansible et de la pile Elasticsearch, Logstash, Kibana (ELK), que nous aborderons au chapitre 14, Surveillance de la plateforme de virtualisation KVM à l'aide de la pile ELK.
Si nous parlons de la façon dont nous virtualisons une machine virtuelle en tant qu'objet, il existe différents types de virtualisation :
- Le partitionnement : Il s'agit d'un type de virtualisation dans lequel un CPU est divisé en différentes parties, et chaque partie fonctionne comme un système individuel. Ce type de solution de virtualisation isole un serveur en partitions, dont chacune peut exécuter un système d'exploitation distinct (par exemple, les partitions logiques IBM (LPAR)).
- Virtualisation complète : Dans la virtualisation complète, une machine virtuelle est utilisée pour simuler du matériel ordinaire sans être consciente du fait qu'elle est virtualisée. Ceci est fait pour des raisons de compatibilité - nous ne devons pas modifier l'OS invité que nous allons exécuter dans une machine virtuelle. Nous pouvons utiliser une approche logicielle et matérielle pour cela : Utilise la traduction binaire pour virtualiser l'exécution de jeux d'instructions sensibles tout en émulant le matériel à l'aide du logiciel, ce qui augmente les frais généraux et a un impact sur l'évolutivité : Supprime la traduction binaire de l'équation tout en se connectant aux fonctions de virtualisation d'un CPU (AMD-V, Intel VT), ce qui signifie que les jeux d'instructions sont exécutés directement sur le CPU hôte. C'est ce que fait KVM (ainsi que d'autres hyperviseurs populaires, tels que ESXi, Hyper-V et Xen).
- Paravirtualisation : Il s'agit d'un type de virtualisation dans lequel le système d'exploitation invité comprend qu'il est en train d'être virtualisé et doit être modifié, ainsi que ses pilotes, afin de pouvoir fonctionner au-dessus de la solution de virtualisation. En même temps, il n'a pas besoin des extensions de virtualisation du CPU pour pouvoir exécuter une machine virtuelle. Par exemple, Xen peut fonctionner comme une solution paravirtualisée.
- La virtualisation hybride : Il s'agit d'un type de virtualisation qui utilise la virtualisation complète et les plus grandes vertus de la paravirtualisation - le fait que le système d'exploitation invité peut être exécuté sans être modifié (complet), et le fait que nous pouvons insérer des pilotes paravirtualisés supplémentaires dans la machine virtuelle pour travailler avec certains aspects spécifiques du travail de la machine virtuelle (le plus souvent, les charges de travail de mémoire à forte intensité d'E/S). Xen et ESXi peuvent également fonctionner en mode de virtualisation hybride.
- Virtualisation basée sur des conteneurs : Il s'agit d'un type de virtualisation d'applications qui utilise des conteneurs. Un conteneur est un objet qui regroupe une application et toutes ses dépendances afin que l'application puisse être mise à l'échelle et déployée rapidement sans avoir besoin d'une machine virtuelle ou d'un hyperviseur. N'oubliez pas qu'il existe des technologies qui peuvent fonctionner à la fois comme hyperviseur et comme hôte de conteneur. Parmi les exemples de ce type de technologie, citons Docker et Podman (un remplacement de Docker dans Red Hat Enterprise Linux 8).
Ensuite, nous allons apprendre à utiliser les hyperviseurs.
Utilisation de l'hyperviseur/gestionnaire de machines virtuelles
Comme son nom l'indique, le gestionnaire de machine virtuelle (VMM) ou hyperviseur est un logiciel chargé de surveiller et de contrôler les machines virtuelles ou les systèmes d'exploitation invités. L'hyperviseur/VMM est chargé d'assurer différentes tâches de gestion de la virtualisation, telles que la fourniture de matériel virtuel, la gestion du cycle de vie des machines virtuelles, la migration des machines virtuelles, l'allocation des ressources en temps réel, la définition de politiques pour la gestion des machines virtuelles, etc. Le VMM/hyperviseur est également chargé de contrôler efficacement les ressources de la plate-forme physique, telles que la traduction de la mémoire et le mappage des entrées/sorties. L'un des principaux avantages du logiciel de virtualisation est sa capacité à exécuter plusieurs invités fonctionnant sur le même système physique ou matériel. Ces systèmes invités multiples peuvent être sur le même système d'exploitation ou sur des systèmes différents. Par exemple, il peut y avoir plusieurs systèmes invités Linux fonctionnant comme invités sur le même système physique. La VMM est chargée d'allouer les ressources demandées par ces systèmes d'exploitation invités. Le matériel du système, tel que le processeur, la mémoire, etc., doit être alloué à ces systèmes d'exploitation invités en fonction de leur configuration, et le VMM peut se charger de cette tâche. Pour cette raison, le VMM est un composant critique dans un environnement de virtualisation.
En termes de types, nous pouvons classer les hyperviseurs en deux catégories : type 1 et type 2.
Hyperviseurs de type 1 et de type 2
Les hyperviseurs sont principalement classés en hyperviseurs de type 1 ou de type 2, en fonction de leur emplacement dans le système ou, en d'autres termes, selon que le système d'exploitation sous-jacent est présent ou non dans le système. Mais il n'existe pas de définition claire ou standard des hyperviseurs de type 1 et de type 2. Si le VMM/hyperviseur fonctionne directement au-dessus du matériel, il est généralement considéré comme un hyperviseur de type 1. Si un système d'exploitation est présent, et si le VMM/hyperviseur fonctionne comme une couche séparée, il sera considéré comme un hyperviseur de type 2. Une fois encore, ce concept est ouvert au débat et il n'existe pas de définition standard à ce sujet. Un hyperviseur de type 1 interagit directement avec le matériel du système ; il n'a pas besoin d'un système d'exploitation hôte. Vous pouvez l'installer directement sur un système bare-metal et le rendre prêt à accueillir des machines virtuelles. Les hyperviseurs de type 1 sont également appelés hyperviseurs bare-metal, embarqués ou natifs. oVirt-node, VMware ESXi/vSphere et Red Hat Enterprise Virtualization Hypervisor (RHEV-H) sont des exemples d'hyperviseurs Linux de type 1. Le diagramme suivant illustre le concept de conception d'un hyperviseur de type 1 :
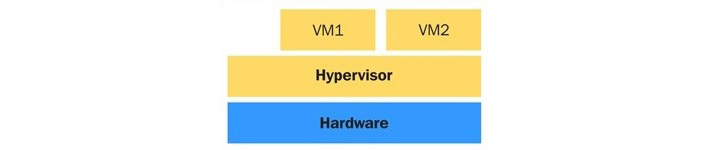
Figure 1.1 - Conception d'un hyperviseur de type 1
Voici les avantages des hyperviseurs de type 1 :
- Facile à installer et à configurer
- De petite taille ; optimisé pour donner la plupart des ressources physiques à l'invité hébergé (machines virtuelles)
- Génère moins de frais généraux car il est livré avec les seules applications nécessaires à l'exécution des machines virtuelles.
- Plus sûr, car les problèmes d'un système invité n'affectent pas les autres systèmes invités fonctionnant sur l'hyperviseur.
Cependant, un hyperviseur de type 1 ne favorise pas la personnalisation. En général, des restrictions s'appliquent lorsque vous essayez d'y installer des applications ou des pilotes tiers.
En revanche, un hyperviseur de type 2 réside au-dessus du système d'exploitation et vous permet d'effectuer de nombreuses personnalisations. Les hyperviseurs de type 2 sont également connus sous le nom d'hyperviseurs hébergés qui dépendent du système d'exploitation hôte pour leur fonctionnement. Le principal avantage des hyperviseurs de type 2 est le large éventail de matériel pris en charge, car le système d'exploitation hôte sous-jacent contrôle l'accès au matériel. Le diagramme suivant illustre le concept de l'hyperviseur de type 2 :
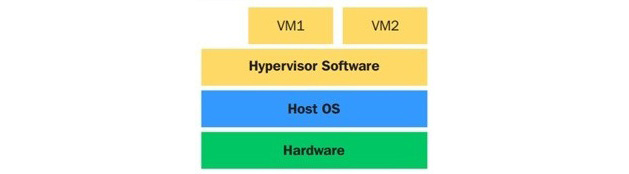
Figure 1.2 - Conception d'un hyperviseur de type 2
Quand utilisons-nous les hyperviseurs de type 1 par rapport aux hyperviseurs de type 2 ? Cela dépend principalement du fait que nous avons déjà un système d'exploitation en cours d'exécution sur un serveur où nous voulons déployer des machines virtuelles. Par exemple, si nous utilisons déjà un bureau Linux sur notre poste de travail, nous n'allons probablement pas formater notre poste de travail et installer un hyperviseur - cela n'aurait aucun sens. C'est un bon exemple d'utilisation d'un hyperviseur de type 2. Les hyperviseurs de type 2 les plus connus sont VMware Player, Workstation, Fusion et Oracle VirtualBox. En revanche, si l'objectif est de créer un serveur que l'on utilisera pour héberger des machines virtuelles, il s'agit d'un hyperviseur de type 1.
Projets de virtualisation open source
Le tableau suivant est une liste de projets de virtualisation open source sous Linux :

Figure 1.3 - Projets de virtualisation open source sous Linux
Dans les sections suivantes, nous aborderons Xen et KVM, qui sont les principales solutions de virtualisation open source sous Linux.
Xen

Xen est né d'un projet de recherche à l'Université de Cambridge. La première version publique de Xen date de 2003. Plus tard, le chef de ce projet à l'Université de Cambridge, Ian Pratt, a cofondé une société appelée XenSource avec Simon Crosby (également de l'Université de Cambridge). Cette société a commencé à développer le projet de manière open source. Le 15 avril 2013, le projet Xen a été transféré à la Fondation Linux en tant que projet collaboratif. La Fondation Linux a lancé une nouvelle marque pour le projet Xen afin de différencier le projet de toute utilisation commerciale de l'ancienne marque Xen. Plus de détails à ce sujet peuvent être trouvés sur https://xenproject.org/.
L'hyperviseur Xen a été porté sur un certain nombre de familles de processeurs, telles que Intel IA-32/64, x86_64, PowerPC, ARM, MIPS, etc.
Le concept de base de Xen comporte quatre éléments principaux :
- L'hyperviseur Xen : La partie intégrante de Xen qui gère l'intercommunication entre le matériel physique et la ou les machines virtuelles. Il gère toutes les interruptions, les temps, les demandes de CPU et de mémoire, et l'interaction matérielle.
- Dom0 : Le domaine de contrôle de Xen, qui contrôle l'environnement d'une machine virtuelle. La partie principale de ce domaine s'appelle QEMU, un logiciel qui émule un système informatique ordinaire en effectuant une traduction binaire pour émuler un CPU.
- Utilitaires de gestion : Utilitaires de ligne de commande et utilitaires d'interface graphique que nous utilisons pour gérer l'environnement Xen global.
- Machines virtuelles (domaines non privilégiés, DomU) : Les invités que nous exécutons sur Xen.
Comme le montre le schéma suivant, le Dom0 est une entité complètement séparée qui contrôle les autres machines virtuelles, tandis que toutes les autres sont joyeusement empilées les unes à côté des autres en utilisant les ressources système fournies par l'hyperviseur :
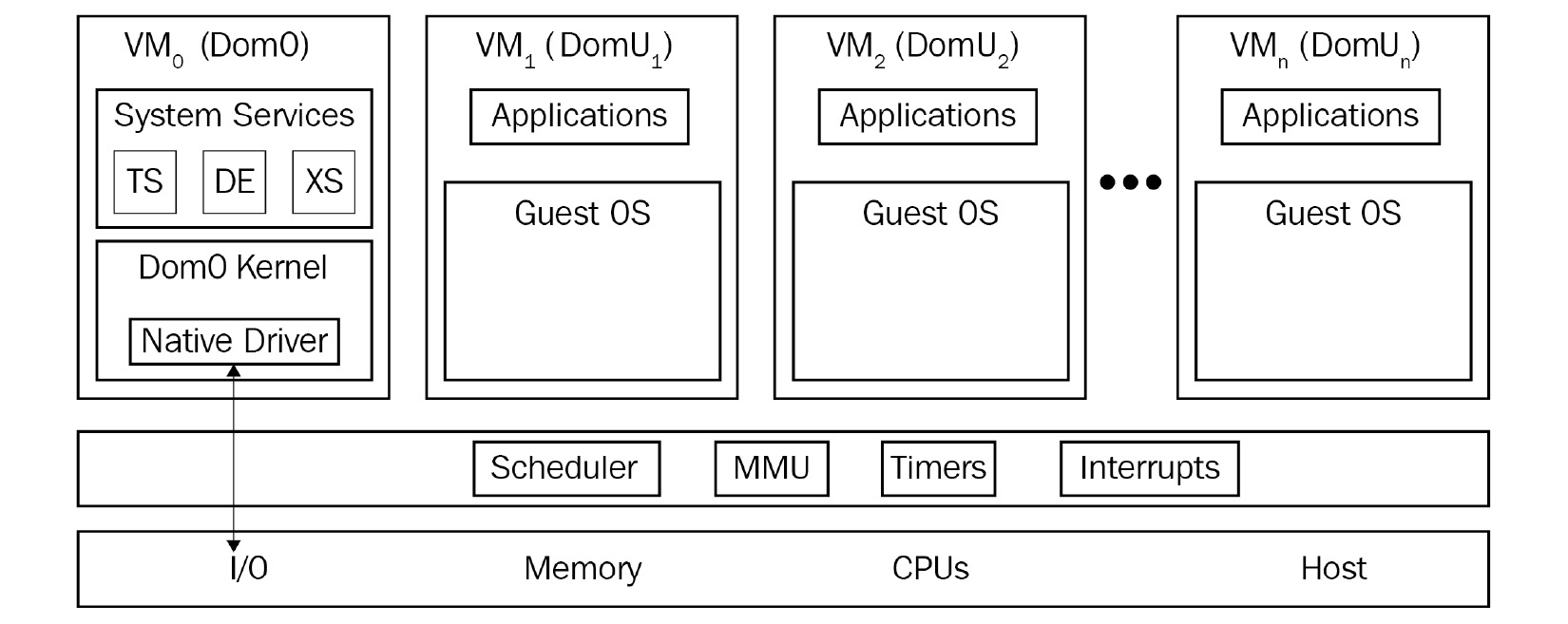
Figure 1.4 – Xen
Certains outils de gestion que nous mentionnerons un peu plus tard dans ce livre sont en fait capables de fonctionner également avec les machines virtuelles Xen. Par exemple, la commande virsh peut être facilement utilisée pour se connecter aux hôtes Xen et les gérer. D'un autre côté, oVirt a été conçu autour de la virtualisation KVM et ce ne serait certainement pas la solution préférée pour gérer votre environnement basé sur Xen.
KVM

KVM représente la dernière génération de virtualisation open source. L'objectif du projet était de créer un hyperviseur moderne qui s'appuie sur l'expérience des générations précédentes de technologies et tire parti du matériel moderne disponible aujourd'hui (VT-x, AMD-V, etc.).
KVM transforme simplement le noyau Linux en hyperviseur lorsque vous installez le module de noyau KVM. Cependant, comme le noyau Linux standard est l'hyperviseur, il bénéficie des modifications qui ont été apportées au noyau standard (support de la mémoire, ordonnanceur, etc.). Les optimisations de ces composants Linux, tels que l'ordonnanceur dans le noyau 3.1, l'amélioration de la virtualisation imbriquée dans les noyaux 4.20+, les nouvelles fonctionnalités d'atténuation des attaques Spectre, la prise en charge de la virtualisation cryptée sécurisée AMD, le passage de l'iGPU d'Intel dans les noyaux 4/5.x, etc. bénéficient à la fois à l'hyperviseur (le système d'exploitation hôte) et aux systèmes d'exploitation invités Linux. Pour les émulations d'E/S, KVM utilise un logiciel utilisateur, QEMU ; il s'agit d'un programme utilisateur qui effectue une émulation matérielle.
QEMU émule le processeur et une longue liste de périphériques tels que le disque, le réseau, le VGA, le PCI, l'USB, les ports série/parallèle, etc. pour construire une pièce complète de matériel virtuel sur laquelle le système d'exploitation invité peut être installé. Cette émulation est alimentée par KVM.
Ce que la virtualisation Linux vous offre dans le nuage
Le cloud est le mot à la mode qui a fait partie de presque toutes les discussions liées à l'informatique au cours des dix dernières années environ. Si nous jetons un coup d'œil à l'histoire du cloud, nous nous rendrons probablement compte qu'Amazon a été le premier acteur clé sur le marché du cloud, avec le lancement d'Amazon Web Services (AWS) et d'Amazon Elastic Compute Cloud (EC2) en 2006. Google Cloud Platform a été lancé en 2008, et Microsoft Azure en 2010. En termes de modèles de clouds d'infrastructure en tant que service (IaaS), ce sont les plus grands fournisseurs de clouds IaaS actuels, bien qu'il en existe d'autres (IBM Cloud, VMware Cloud on AWS, Oracle Cloud et Alibaba Cloud, pour n'en citer que quelques-uns). Si vous parcourez cette liste, vous vous rendrez vite compte que la plupart de ces plateformes de cloud computing sont basées sur Linux (à titre d'exemple, Amazon utilise Xen et KVM, tandis que Google Cloud utilise la virtualisation KVM).
Actuellement, il existe trois principaux projets de clouds open source qui utilisent la virtualisation Linux pour construire des solutions IaaS pour le cloud privé et/ou hybride :
- OpenStack

Un système d'exploitation de nuage entièrement open source qui se compose de plusieurs sous-projets open source qui fournissent tous les blocs de construction pour créer un nuage IaaS. KVM (virtualisation Linux) est l'hyperviseur le plus utilisé (et le mieux supporté) dans les déploiements OpenStack. Il est régi par la fondation OpenStack, indépendante des fournisseurs. La façon de construire un nuage OpenStack à l'aide de KVM sera expliquée en détail dans le chapitre 12, Mise à l'échelle de KVM avec OpenStack.
- CloudStack

Il s'agit d'un autre projet de nuage open source contrôlé par l'Apache Software Foundation (ASF) utilisé pour construire et gérer des nuages IaaS multitenant hautement évolutifs et entièrement compatible avec les API EC2/S3. Bien qu'il prenne en charge tous les hyperviseurs Linux de premier niveau, la plupart des utilisateurs de CloudStack choisissent Xen car il est étroitement intégré à CloudStack.
- Eucalyptus

Il s'agit d'un logiciel de cloud privé compatible avec AWS que les organisations peuvent utiliser afin de réduire le coût de leur cloud public et de reprendre le contrôle de la sécurité et des performances. Il prend en charge à la fois Xen et KVM en tant que fournisseur de ressources informatiques.
Il existe d'autres questions importantes à prendre en compte lorsque vous discutez d'OpenStack, au-delà des éléments techniques que nous avons abordés jusqu'à présent dans ce chapitre. L'un des concepts les plus importants dans le domaine de l'informatique aujourd'hui est la possibilité de faire fonctionner un environnement (purement virtualisé, ou un environnement en nuage) qui comprend différents types de solutions (telles que des solutions de virtualisation) en utilisant une sorte de couche de gestion capable de travailler avec différentes solutions en même temps. Prenons l'exemple d'OpenStack. Si vous parcourez la documentation d'OpenStack, vous vous rendrez vite compte qu'OpenStack prend en charge plus de 10 solutions de virtualisation différentes, dont les suivantes :
- KVM
- Xen (via libvirt)
- LXC (conteneurs Linux)
- Microsoft Hyper-V
- VMware ESXi
- Citrix XenServer
- User Mode Linux (UML)
- PowerVM (plate-forme IBM Power 5-9)
- Virtuozzo (solution hyperconvergée qui peut utiliser des machines virtuelles, du stockage et des conteneurs)
- z/VM (solution de virtualisation pour les serveurs IBM Z et IBM LinuxONE)
Cela nous amène aux environnements multi-clouds qui pourraient couvrir différentes architectures de CPU, différents hyperviseurs et d'autres technologies telles que les hyperviseurs - le tout sous le même ensemble d'outils de gestion. Ce n'est qu'une des choses que vous pouvez faire avec OpenStack. Nous reviendrons sur le sujet d'OpenStack plus tard dans ce livre, plus précisément au chapitre 12, Scaling Out KVM with OpenStack.
Résumé
Dans ce chapitre, nous avons abordé les bases de la virtualisation et ses différents types. Il est utile de garder à l'esprit l'importance de la virtualisation dans le monde informatique à grande échelle d'aujourd'hui, car il est bon de savoir comment ces concepts peuvent être liés pour créer une image plus large - de grands environnements virtualisés et des environnements en nuage. Les technologies basées sur le cloud seront abordées ultérieurement de manière beaucoup plus détaillée - considérez ce que nous avons mentionné jusqu'à présent comme une entrée en matière ; le plat principal est encore à venir. Le chapitre suivant est consacré à la star de notre livre : l'hyperviseur KVM et ses utilitaires.
Chapitre 2 : KVM comme solution de virtualisation
Dans ce chapitre, nous allons aborder la virtualisation en tant que concept et sa mise en œuvre via libvirt, Quick Emulator (QEMU) et KVM. En réalité, si nous voulons expliquer comment la virtualisation fonctionne et pourquoi la virtualisation KVM est un élément fondamental de l'informatique du 21ème siècle, nous devons commencer par expliquer le contexte technique des CPU multi-cœurs et de la virtualisation ; et cela est impossible à faire sans se plonger dans la théorie des CPU et des systèmes d'exploitation afin d'arriver à ce qui nous intéresse vraiment - ce que sont les hyperviseurs et comment la virtualisation fonctionne réellement.
Dans ce chapitre, nous aborderons les sujets suivants :
- La virtualisation en tant que concept (les deux autres sortent du cadre historique)
La virtualisation en tant que concept
La virtualisation est une approche informatique qui dissocie le matériel du logiciel. Elle fournit une approche meilleure, plus efficace et programmatique de la division et du partage des ressources entre diverses charges de travail - des machines virtuelles exécutant des systèmes d'exploitation et des applications par-dessus.
Si nous devions comparer l'informatique physique traditionnelle du passé avec la virtualisation, nous pourrions dire qu'en virtualisant, nous avons la possibilité d'exécuter plusieurs systèmes d'exploitation invités (plusieurs serveurs virtuels) sur le même matériel (le même serveur physique). Si nous utilisons un hyperviseur de type 1 (expliqué au chapitre 1, Comprendre la virtualisation de Linux), cela signifie que l'hyperviseur va être chargé de permettre aux serveurs virtuels d'accéder au matériel physique. En effet, plus d'un serveur virtuel utilise le même matériel que les autres serveurs virtuels sur le même serveur physique. Cela est généralement pris en charge par une sorte d'algorithme de planification mis en œuvre de manière programmatique dans les hyperviseurs afin d'obtenir une plus grande efficacité du même serveur physique.
Environnements virtualisés et physiques
Essayons de visualiser ces deux approches - physique et virtuelle. Dans un serveur physique, nous installons un système d'exploitation directement sur le matériel du serveur et nous exécutons des applications au-dessus de ce système. Le schéma suivant nous montre comment cette approche fonctionne :
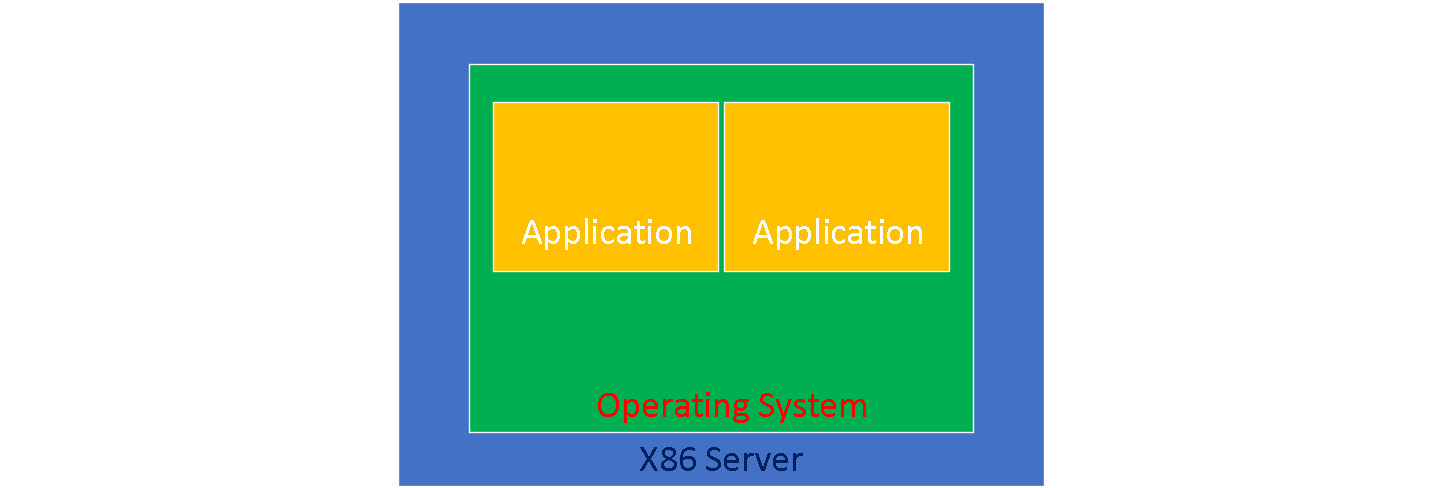
Figure 2.1 - Serveur physique
Dans un monde virtualisé, nous utilisons un hyperviseur (tel que KVM) et des machines virtuelles au-dessus de cet hyperviseur. À l'intérieur de ces machines virtuelles, nous exécutons le même système d'exploitation et les mêmes applications, tout comme dans le serveur physique. L'approche virtualisée est illustrée dans le diagramme suivant :
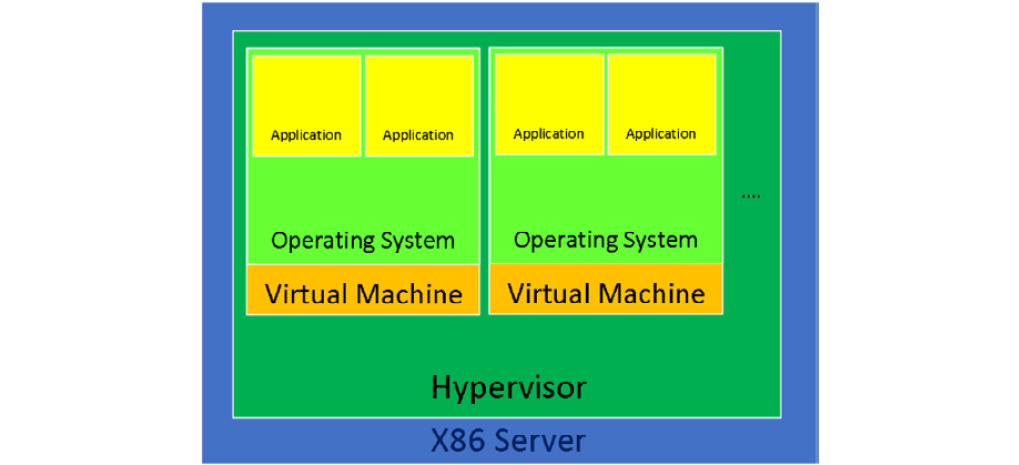
Figure 2.2 - Hyperviseur et deux machines virtuelles
Il existe encore divers scénarios dans lesquels l'approche physique sera nécessaire. Par exemple, il y a encore des milliers d'applications sur des serveurs physiques dans le monde entier parce que ces serveurs ne peuvent pas être virtualisés. Il y a différentes raisons pour lesquelles ils ne peuvent pas être virtualisés. Par exemple, la raison la plus courante est en fait la plus simple : ces applications sont peut-être exécutées sur un système d'exploitation qui ne figure pas sur la liste des systèmes d'exploitation pris en charge par le fournisseur du logiciel de virtualisation. Cela peut signifier que vous ne pouvez pas virtualiser cette combinaison OS/application parce que cet OS ne prend pas en charge certains matériels virtualisés, le plus souvent un réseau ou un adaptateur de stockage. La même idée générale s'applique également au cloud : déplacer les choses vers le cloud n'est pas toujours la meilleure idée, comme nous le décrirons plus loin dans ce livre.
Pourquoi la virtualisation est-elle si importante ?
Un grand nombre d'applications que nous exécutons aujourd'hui ne s'adaptent pas bien (en ajoutant plus de CPU, de mémoire ou d'autres ressources) - elles ne sont tout simplement pas programmées de cette façon ou ne peuvent pas être sérieusement parallélisées. Cela signifie que si une application ne peut pas utiliser toutes les ressources à sa disposition, un serveur va avoir beaucoup d'espace libre - et cette fois, nous ne parlons pas d'espace libre sur le disque ; nous faisons en fait référence à l'espace libre de calcul, c'est-à-dire l'espace libre au niveau du CPU et de la mémoire. Cela signifie que nous sous-utilisons les capacités du serveur que nous avons payé, dans l'intention de l'utiliser pleinement et non partiellement.
Il existe d'autres raisons pour lesquelles l'efficacité et les approches programmatiques sont si importantes. Le fait est qu'au-delà de leur guerre de communiqués de presse dans la période 2003-2005, lorsqu'il s'agissait de se vanter de la fréquence du CPU (qui équivaut à la vitesse du CPU), Intel et AMD se sont heurtés à un mur en termes de développement du concept de CPU monocœur. Ils ne pouvaient tout simplement pas intégrer autant d'éléments supplémentaires dans le processeur (que ce soit pour l'exécution ou le cache) et/ou augmenter la vitesse du cœur unique sans compromettre sérieusement la manière dont les processeurs étaient alimentés en courant électrique. Cela signifie qu'en fin de compte, cette approche compromettait la fiabilité du CPU et de l'ensemble du système qu'il faisait fonctionner. Si vous souhaitez en savoir plus à ce sujet, nous vous suggérons de consulter les articles consacrés aux processeurs à architecture NetBurst d'Intel (par exemple, le cœur Prescott) et à leur petit frère, le Pentium D (le cœur Smithfield), qui était en fait constitué de deux cœurs Prescott collés l'un à l'autre, de sorte que le résultat final était un processeur à double cœur. Un processeur à double cœur très, très chaud.
Quelques générations auparavant, Intel et AMD ont essayé et testé d'autres techniques pour appliquer le principe des unités d'exécution multiples par système. Par exemple, nous avions les systèmes Intel Pentium Pro à deux sockets et les systèmes AMD Opteron à deux et quatre sockets. Nous y reviendrons plus tard dans ce livre lorsque nous commencerons à aborder certains aspects très importants de la virtualisation (par exemple, l'accès mémoire non unifié (NUMA)).
Ainsi, quel que soit le point de vue que l'on adopte, lorsque les processeurs pour PC ont commencé à être dotés de plusieurs cœurs en 2005 (AMD a été le premier à commercialiser un processeur multi-cœurs pour serveur et Intel a été le premier à commercialiser un processeur multi-cœurs pour ordinateur de bureau), c'était la seule façon rationnelle d'avancer. Ces cœurs étaient plus petits, plus efficaces (consommant moins d'énergie) et constituaient généralement une meilleure approche à long terme. Bien entendu, cela signifiait que les systèmes d'exploitation et les applications devaient être profondément remaniés si des entreprises telles que Microsoft et Oracle voulaient utiliser leurs applications et profiter des avantages d'un serveur multicœur.
En conclusion, pour les serveurs basés sur PC, du point de vue du CPU, le passage aux CPU multi-cœurs a été un moment opportun pour commencer à travailler vers la virtualisation en tant que concept que nous connaissons et aimons aujourd'hui.
Parallèlement à ces développements, les CPU ont reçu d'autres ajouts - par exemple, des registres CPU supplémentaires qui peuvent gérer des types d'opérations spécifiques. Beaucoup de gens ont entendu parler des jeux d'instructions tels que MMX, SSE, SSE2, SSE3, SSE4.x, AVX, AVX2, AES, etc. Ces jeux d'instructions sont tous très importants aujourd'hui, car ils nous donnent la possibilité de décharger certains types d'instructions dans un registre spécifique du CPU. Cela signifie que ces instructions ne doivent pas être exécutées sur un CPU en tant que périphérique série général, qui exécute ces tâches plus lentement. Au lieu de cela, ces instructions peuvent être envoyées à un registre spécifique du CPU qui est spécialisé pour ces instructions. C'est comme si l'on disposait de mini-accélérateurs séparés sur un processeur qui pourraient exécuter certains éléments de la pile logicielle sans monopoliser le pipeline général du processeur. L'un de ces ajouts était Virtual Machine Extensions (VMX) pour Intel, ou AMD Virtualization (AMD-V), qui nous permettent tous deux d'avoir une prise en charge complète de la virtualisation basée sur le matériel pour leurs plates-formes respectives.
- Prise en charge de la traduction d'adresses de second niveau, de l'indexation de virtualisation rapide et des tables de pages étendues (SLAT/RVI/EPT) : Il s'agit de la technologie de CPU qu'un hyperviseur utilise pour disposer d'une carte d'adresses de mémoire virtuelle à physique. Les machines virtuelles fonctionnent dans un espace mémoire virtuel qui peut être éparpillé sur toute la mémoire physique. En utilisant une carte supplémentaire telle que SLAT/EPT (mise en œuvre via une Translation Lookaside Buffer ou TLB supplémentaire), vous réduisez la latence de l'accès à la mémoire. Si nous ne disposions pas d'une telle technologie, nous devrions accéder aux adresses physiques de la mémoire de l'ordinateur, ce qui serait désordonné, peu sûr et générateur de latence. Pour éviter toute confusion, EPT est le nom donné par Intel à la technologie SLAT dans ses processeurs (AMD utilise la terminologie RVI, tandis qu'Intel utilise la terminologie EPT).
- Support Intel VT ou AMD-V : Si un processeur Intel possède VT (ou un processeur AMD possède AMD-V), cela signifie qu'il prend en charge les extensions de virtualisation matérielle et la virtualisation complète.
- Prise en charge du mode long, ce qui signifie que le CPU prend en charge le mode 64 bits. Sans une architecture 64 bits, la virtualisation serait pratiquement inutile car vous n'auriez que 4 Go de mémoire à donner aux machines virtuelles (ce qui est une limitation de l'architecture 32 bits). En utilisant une architecture 64 bits, nous pouvons allouer beaucoup plus de mémoire (en fonction du processeur utilisé), ce qui signifie plus de possibilités d'alimenter les machines virtuelles en mémoire, sans quoi le concept de virtualisation n'aurait aucun sens dans l'espace informatique du 21e siècle.
La possibilité de disposer d'une virtualisation IOMMU (Input/Output Memory Management Unit) (comme AMD-Vi, Intel VT-d et les tables stage 2 sur ARM), ce qui signifie que nous permettons aux machines virtuelles d'accéder directement au matériel périphérique (cartes graphiques, contrôleurs de stockage, périphériques réseau, etc.) Cette fonctionnalité doit être activée à la fois du côté du CPU et du côté du chipset/firmware de la carte mère. - La possibilité de faire de la virtualisation d'entrée-sortie à racine unique (SR/IOV), qui nous permet de transmettre directement un périphérique PCI Express (par exemple, un port Ethernet) à plusieurs machines virtuelles. L'aspect clé de SR-IOV est sa capacité à partager un périphérique physique avec plusieurs machines virtuelles via une fonctionnalité appelée Fonctions Virtuelles (VFs). Cette fonctionnalité nécessite la prise en charge du matériel et des pilotes.
- La possibilité de faire du PCI passthrough, ce qui signifie que nous pouvons prendre une carte connectée PCI Express (par exemple, une carte vidéo) connectée à une carte mère de serveur et la présenter à une machine virtuelle comme si cette carte était directement connectée à la machine virtuelle via une fonctionnalité appelée Physical Functions (PFs). Cela signifie qu'il faut contourner les différents niveaux de l'hyperviseur par lesquels la connexion se ferait normalement.
- La prise en charge du module TPM (Trusted Platform Module), qui est généralement implémenté comme une puce supplémentaire sur la carte mère. L'utilisation du TPM peut présenter de nombreux avantages en termes de sécurité car il peut être utilisé pour fournir un support cryptographique (c'est-à-dire pour créer, sauvegarder et sécuriser l'utilisation de clés cryptographiques). Il y a eu pas mal de buzz dans le monde Linux autour de l'utilisation de TPM avec la virtualisation KVM, ce qui a conduit à l'open sourcing par Intel de la pile TPM2 à l'été 2018.
Lorsque vous discutez de SR-IOV et de PCI passthrough, veillez à prendre note des fonctionnalités de base, appelées PF et VF. Ces deux mots-clés vous permettront de vous rappeler plus facilement où (au niveau physique ou virtuel) et comment (directement ou via un hyperviseur) les périphériques sont transmis à leurs machines virtuelles respectives. Ces capacités sont très importantes pour les entreprises et pour un certain nombre de scénarios spécifiques. À titre d'exemple, il est littéralement impossible d'avoir une solution d'infrastructure de bureau virtuel (VDI) avec des machines virtuelles de niveau poste de travail que vous pouvez utiliser pour exécuter AutoCAD et des applications similaires sans ces capacités. En effet, les graphiques intégrés aux CPU sont tout simplement trop lents pour permettre une exécution correcte. C'est à ce moment-là que vous commencez à ajouter des GPU à vos serveurs, de sorte que vous puissiez utiliser un hyperviseur pour transmettre l'ensemble du GPU ou des parties de celui-ci à une ou plusieurs machines virtuelles.
En termes de mémoire système, il y a également plusieurs sujets à prendre en compte. AMD a commencé à intégrer des contrôleurs de mémoire dans les CPU à partir de l'Athlon 64, soit des années avant qu'Intel ne le fasse (Intel l'a fait en premier avec le cœur de CPU Nehalem, qui a été introduit en 2008). L'intégration d'un contrôleur de mémoire dans un CPU signifiait que votre système avait moins de latence lorsque le CPU accédait à la mémoire pour des opérations d'E/S de mémoire. Auparavant, le contrôleur de mémoire était intégré à ce que l'on appelait une puce NorthBridge, qui était une puce distincte sur la carte mère d'un système, chargée de tous les bus rapides et de la mémoire. Mais cela signifie une latence supplémentaire, surtout lorsque vous essayez d'étendre ce principe aux CPU multi-socket et multi-core. De plus, avec l'introduction de l'Athlon 64 sur Socket 939, AMD est passé à une architecture de mémoire à double canal, qui est maintenant un thème familier sur le marché des ordinateurs de bureau et des serveurs. Les contrôleurs de mémoire à triple et quadruple canaux sont des standards de facto dans les serveurs. Certains des derniers processeurs Intel Xeon prennent en charge les contrôleurs de mémoire à six canaux, et les processeurs AMD EPYC prennent également en charge les contrôleurs de mémoire à huit canaux. Cela a d'énormes répercussions sur la bande passante et la latence globales de la mémoire, ce qui, à son tour, a d'énormes répercussions sur la vitesse des applications sensibles à la mémoire, tant sur les serveurs physiques que virtuels.
Pourquoi est-ce important ? Plus le nombre de canaux est élevé et plus la latence est faible, plus la bande passante entre le processeur et la mémoire est importante. Et cela est très, très souhaitable pour un grand nombre de charges de travail dans l'espace informatique actuel (par exemple, les bases de données).
Exigences logicielles pour la virtualisation
Maintenant que nous avons couvert les aspects matériels de base de la virtualisation, passons à l'aspect logiciel de la virtualisation. Pour ce faire, nous devons aborder un certain jargon en informatique. Ceci étant dit, commençons par ce que l'on appelle les anneaux de protection. En informatique, il existe différents domaines de protection hiérarchiques/anneaux privilégiés. Il s'agit des mécanismes qui protègent les données ou les failles en fonction de la sécurité appliquée lors de l'accès aux ressources d'un système informatique. Ces domaines de protection contribuent à la sécurité d'un système informatique. En imaginant ces anneaux de protection comme des zones d'instruction, on peut les représenter par le schéma suivant :
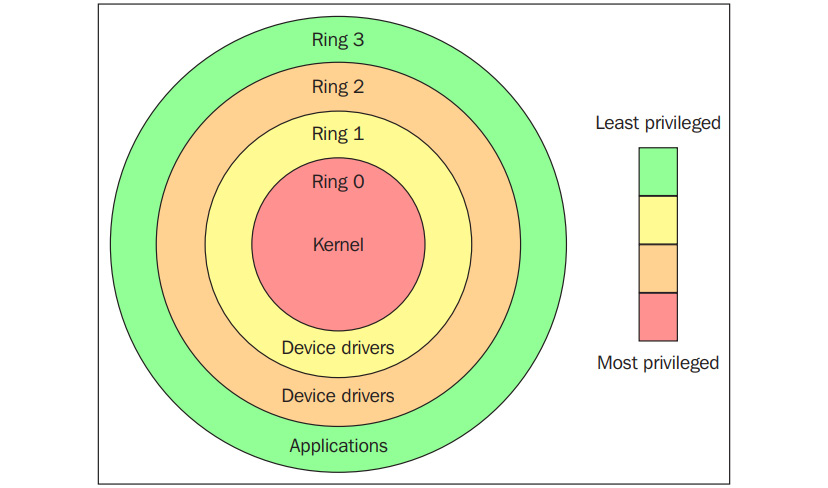
Figure 2.3 - Anneaux de protection (source : https://en.wikipedia.org/wiki/Protection_ring)
Comme le montre le schéma précédent, les anneaux de protection sont numérotés du plus privilégié au moins privilégié. L'anneau 0 est le niveau le plus privilégié et interagit directement avec le matériel physique, tel que le CPU et la mémoire. Les ressources, telles que la mémoire, les ports d'E/S et les instructions du CPU, sont protégées par ces anneaux privilégiés. Les anneaux 1 et 2 sont pour la plupart inutilisés. La plupart des systèmes à usage général n'utilisent que deux anneaux, même si le matériel sur lequel ils fonctionnent fournit plus de modes CPU que cela. Les deux principaux modes du CPU sont le mode noyau et le mode utilisateur, qui sont également liés à la manière dont les processus sont exécutés. Vous pouvez en savoir plus à ce sujet en cliquant sur le lien suivant : https://access.redhat.com/sites/default/files/attachments/processstates_20120831.pdf. Du point de vue d'un système d'exploitation, l'anneau 0 est appelé mode noyau/mode superviseur et l'anneau 3 est le mode utilisateur. Comme vous l'avez peut-être supposé, les applications fonctionnent dans l'anneau 3.
Les systèmes d'exploitation tels que Linux et Windows utilisent le mode superviseur/noyau et le mode utilisateur. Ce mode ne peut pratiquement rien faire pour le monde extérieur sans faire appel au noyau ou sans son aide en raison de son accès restreint à la mémoire, à l'unité centrale et aux ports d'entrée/sortie. Les noyaux peuvent fonctionner en mode privilégié, ce qui signifie qu'ils peuvent fonctionner sur l'anneau 0. Pour exécuter des fonctions spécialisées, le code du mode utilisateur (toutes les applications qui s'exécutent dans l'anneau 3) doit effectuer un appel système vers le mode superviseur ou même vers l'espace noyau, où le code de confiance du système d'exploitation exécutera la tâche nécessaire et renverra l'exécution à l'espace utilisateur. En bref, le système d'exploitation fonctionne dans l'anneau 0 dans un environnement normal. Il a besoin du niveau le plus privilégié pour gérer les ressources et donner accès au matériel. Le diagramme suivant explique cela :
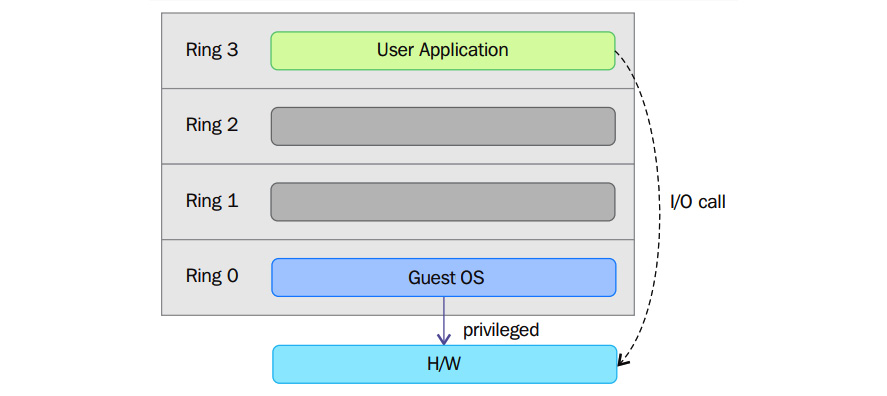
Figure 2.4 - Appel du système en mode superviseur
Les anneaux au-dessus de 0 exécutent des instructions dans un mode de processeur appelé non protégé. L'hyperviseur/Virtual Machine Monitor (VMM) doit accéder à la mémoire, au processeur et aux périphériques d'E/S de l'hôte. Étant donné que seul le code s'exécutant dans l'anneau 0 est autorisé à effectuer ces opérations, il doit s'exécuter dans l'anneau le plus privilégié, à savoir l'anneau 0, et doit être placé à côté du noyau. Sans prise en charge spécifique de la virtualisation matérielle, l'hyperviseur ou le VMM s'exécute dans l'anneau 0, ce qui bloque le système d'exploitation de la machine virtuelle dans cet anneau. Un système d'exploitation installé dans une machine virtuelle est également censé accéder à toutes les ressources puisqu'il ne connaît pas la couche de virtualisation ; pour ce faire, il doit fonctionner dans l'anneau 0, comme le VMM. Étant donné qu'un seul noyau peut fonctionner dans l'anneau 0 à la fois, les systèmes d'exploitation invités doivent fonctionner dans un autre anneau avec moins de privilèges ou être modifiés pour fonctionner en mode utilisateur.
Cela a conduit à l'introduction de deux méthodes de virtualisation appelées virtualisation complète et paravirtualisation, que nous avons mentionnées précédemment. Essayons maintenant de les expliquer d'une manière plus technique.
Virtualisation complète
Dans la virtualisation complète, les instructions privilégiées sont émulées pour surmonter les limitations qui résultent de l'exécution du système d'exploitation invité dans l'anneau 1 et du VMM dans l'anneau 0. La virtualisation complète a été mise en œuvre dans les VMM x86 de première génération. Elle s'appuie sur des techniques telles que la traduction binaire pour piéger et virtualiser l'exécution de certaines instructions sensibles et non virtualisables. Ceci étant dit, dans la traduction binaire, certains appels système sont interprétés et réécrits dynamiquement. Le schéma suivant montre comment le système d'exploitation invité accède au matériel de l'ordinateur hôte par l'anneau 1 pour les instructions privilégiées et comment les instructions non privilégiées sont exécutées sans l'intervention de l'anneau 1 :
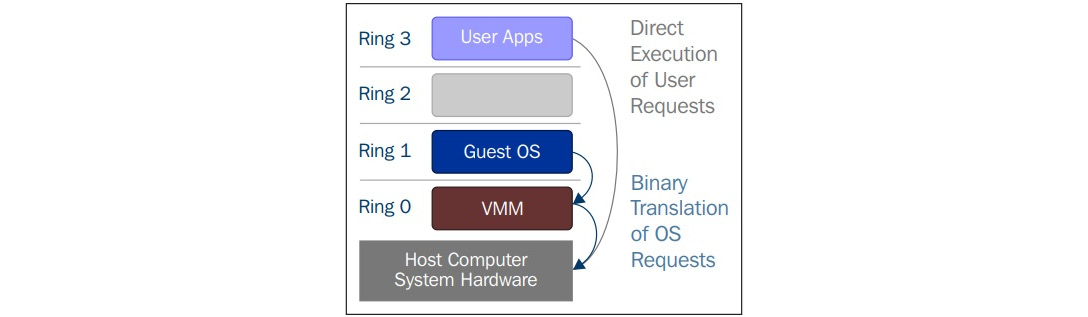
Figure 2.5 - Traduction binaire
Avec cette approche, les instructions critiques sont découvertes (statiquement ou dynamiquement au moment de l'exécution) et remplacées par des pièges dans la VMM qui doivent être émulés en logiciel. Une traduction binaire peut entraîner un surcoût de performance important par rapport à une machine virtuelle fonctionnant sur des architectures nativement virtualisées. Ceci est illustré dans le diagramme suivant :
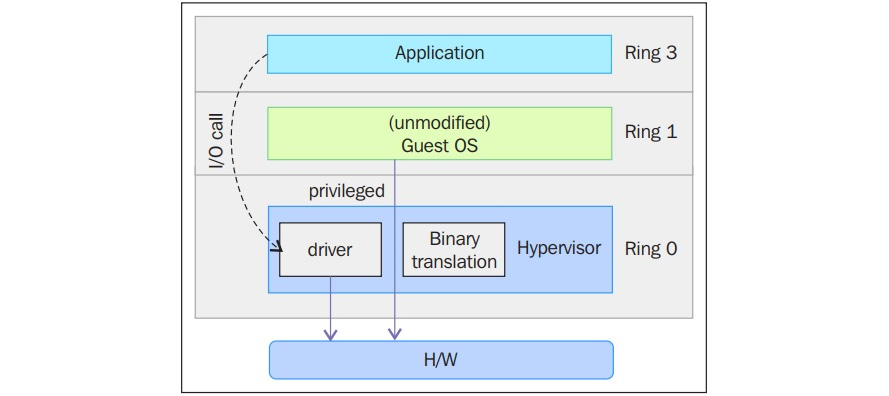
Figure 2.6 - Virtualisation complète
Cependant, comme le montre le schéma précédent, lorsque nous utilisons la virtualisation complète, nous pouvons utiliser les OS invités non modifiés. Cela signifie que nous ne devons pas modifier le noyau invité pour qu'il s'exécute sur une VMM. Lorsque le noyau invité exécute des opérations privilégiées, la VMM fournit l'émulation du CPU pour gérer et modifier les opérations protégées du CPU. Toutefois, comme nous l'avons mentionné précédemment, cela entraîne une surcharge de performance par rapport à l'autre mode de virtualisation, appelé paravirtualisation.
Paravirtualisation
Dans la paravirtualisation, le système d'exploitation de l'invité doit être modifié pour permettre à ces instructions d'accéder à l'anneau 0. En d'autres termes, le système d'exploitation doit être modifié pour communiquer entre le VMM/hyperviseur et l'invité par le biais du chemin backend (hypercalls) :
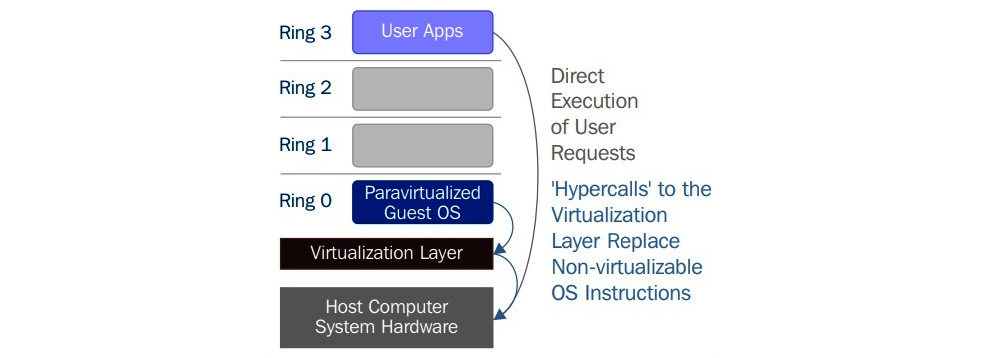
Figure 2.7 - Paravirtualisation
La paravirtualisation (https://en.wikipedia.org/wiki/Paravirtualization) est une technique dans laquelle l'hyperviseur fournit une API, et le système d'exploitation de la machine virtuelle invitée appelle cette API, ce qui nécessite des modifications du système d'exploitation hôte. Les appels d'instructions privilégiées sont échangés avec les fonctions de l'API fournies par la VMM. Dans ce cas, le système d'exploitation invité modifié peut s'exécuter dans l'anneau 0.
Comme vous pouvez le constater, avec cette technique, le noyau invité est modifié pour fonctionner sur la VMM. En d'autres termes, le noyau invité sait qu'il a été virtualisé. Les instructions/opérations privilégiées qui sont censées s'exécuter dans l'anneau 0 ont été remplacées par des appels connus sous le nom d'hypercalls, qui communiquent avec le VMM. Ces hyperappels invoquent le VMM pour qu'il exécute la tâche au nom du noyau invité. Étant donné que le noyau invité peut communiquer directement avec le VMM via les hyperappels, cette technique permet d'obtenir des performances supérieures à celles de la virtualisation complète. Toutefois, elle nécessite un noyau invité spécialisé, conscient de la paravirtualisation et doté du support logiciel nécessaire.
Les concepts de paravirtualisation et de virtualisation complète étaient une façon courante de faire de la virtualisation, mais pas de la meilleure façon possible et gérable. C'est là que la virtualisation assistée par matériel entre en jeu, comme nous allons le décrire dans la section suivante.
La virtualisation assistée par le matériel
Intel et AMD ont réalisé que la virtualisation complète et la paravirtualisation constituaient les principaux défis de la virtualisation sur l'architecture x86 (le champ d'application de cet ouvrage étant limité à l'architecture x86, nous aborderons principalement l'évolution de cette architecture ici) en raison de la surcharge de performance et de la complexité de la conception et de la maintenance de la solution. Intel et AMD ont créé indépendamment de nouvelles extensions de processeur de l'architecture x86, appelées respectivement Intel VT-x et AMD-V. Sur l'architecture Itanium, la virtualisation assistée par matériel est connue sous le nom de VT-i. La virtualisation assistée par le matériel est une méthode de virtualisation de plate-forme conçue pour utiliser efficacement la virtualisation complète avec les capacités du matériel. Divers fournisseurs appellent cette technologie par différents noms, notamment virtualisation accélérée, machine virtuelle matérielle et virtualisation native.
Pour une meilleure prise en charge de la virtualisation, Intel et AMD ont introduit la technologie de virtualisation (VT) et la machine virtuelle sécurisée (SVM), respectivement, comme extensions du jeu d'instructions IA-32. Ces extensions permettent au VMM/hyperviseur d'exécuter un OS invité qui s'attend à fonctionner en mode noyau, dans des anneaux privilégiés inférieurs. La virtualisation assistée par le matériel propose non seulement de nouvelles instructions mais introduit également un nouveau niveau d'accès privilégié, appelé anneau -1, dans lequel l'hyperviseur/VMM peut fonctionner. Ainsi, les machines virtuelles invitées peuvent fonctionner dans l'anneau 0. Avec la virtualisation assistée par matériel, le système d'exploitation a un accès direct aux ressources sans aucune émulation ou modification du système d'exploitation. L'hyperviseur ou le VMM peut maintenant fonctionner au niveau de privilège nouvellement introduit, l'anneau -1, avec les OS invités fonctionnant sur l'anneau 0. En outre, avec la virtualisation assistée par matériel, le VMM/hyperviseur est détendu et doit effectuer moins de travail par rapport aux autres techniques mentionnées, ce qui réduit l'overhead de performance. Cette capacité à fonctionner directement dans l'anneau -1 peut être décrite à l'aide du diagramme suivant :
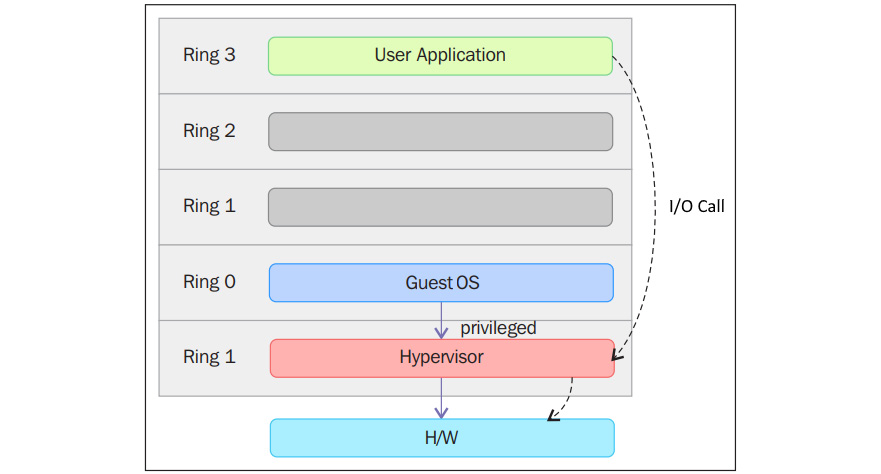
Figure 2.8 - Virtualisation assistée par le matériel
En termes simples, ce matériel de virtualisation nous fournit un support pour construire le VMM et assure également l'isolation d'un OS invité. Cela nous aide à obtenir de meilleures performances et à éviter la complexité de la conception d'une solution de virtualisation. Les techniques de virtualisation modernes utilisent cette caractéristique pour fournir la virtualisation. Un exemple est KVM, dont nous allons parler en détail tout au long de ce livre.
Maintenant que nous avons couvert les aspects matériels et logiciels de la virtualisation, voyons comment tout cela s'applique à KVM en tant que technologie de virtualisation.
Source : https://www.packtpub.com/product/mastering-kvm-virtualization-second-edition/9781838828714