À la découverte des conteneurs Docker


Au sommaire :
- 1-Qu'est-ce qu'un processus ?
- 2-Qu'est-ce qu'un conteneur Docker ?
- 3-Les deux briques de base des conteneurs.
- 4-Conteneurs vs machines virtuelles.
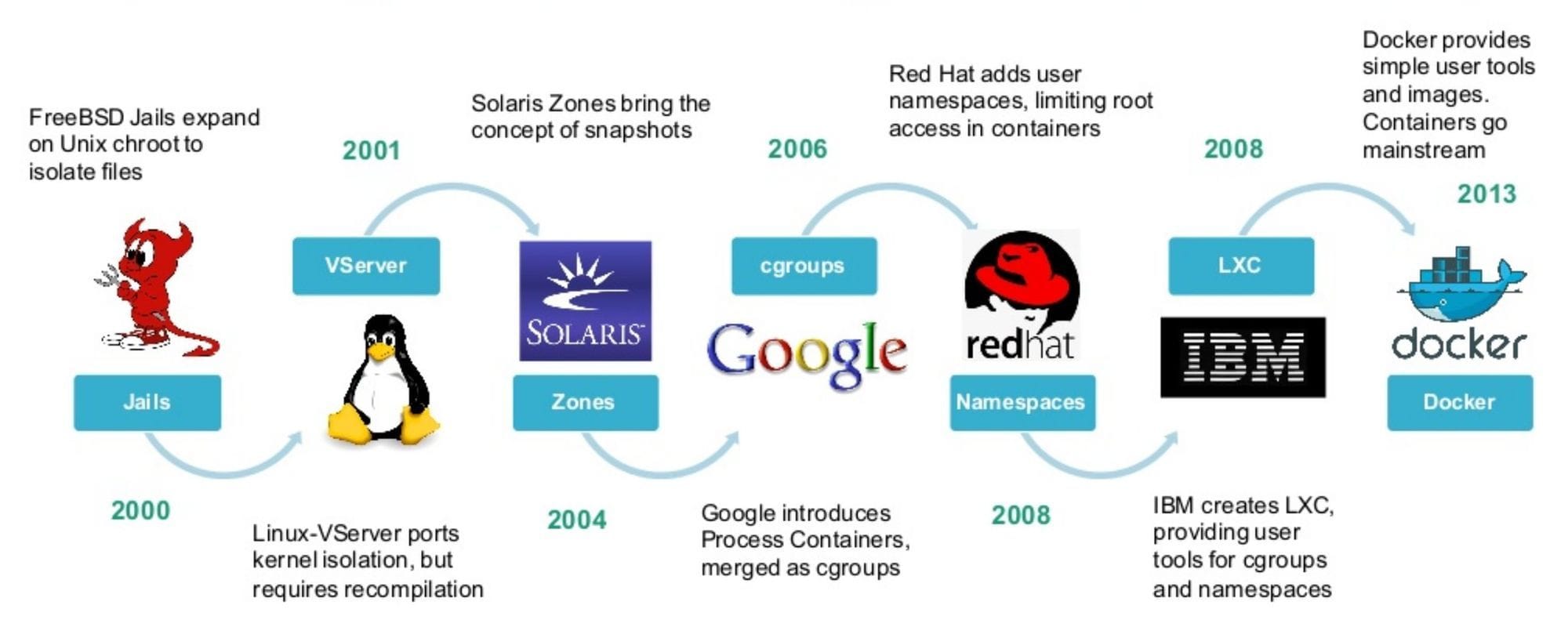
Pour les retardataires, voici un historique de l'histoire des conteneurs.
1-Qu'est-ce qu'un processus ?
Un processus est une instance d'un logiciel en cours d’exécution dans l'espace utilisateur (user space) et son exécution est orchestré par le noyau du système hôte.
Lorsqu'il est exécuté, il doit accéder à différentes ressources (processeur, mémoire, stockage, réseau, etc.) en faisant ce qu'on appelle un appel système (system call) dans l'espace noyau (kernel space).
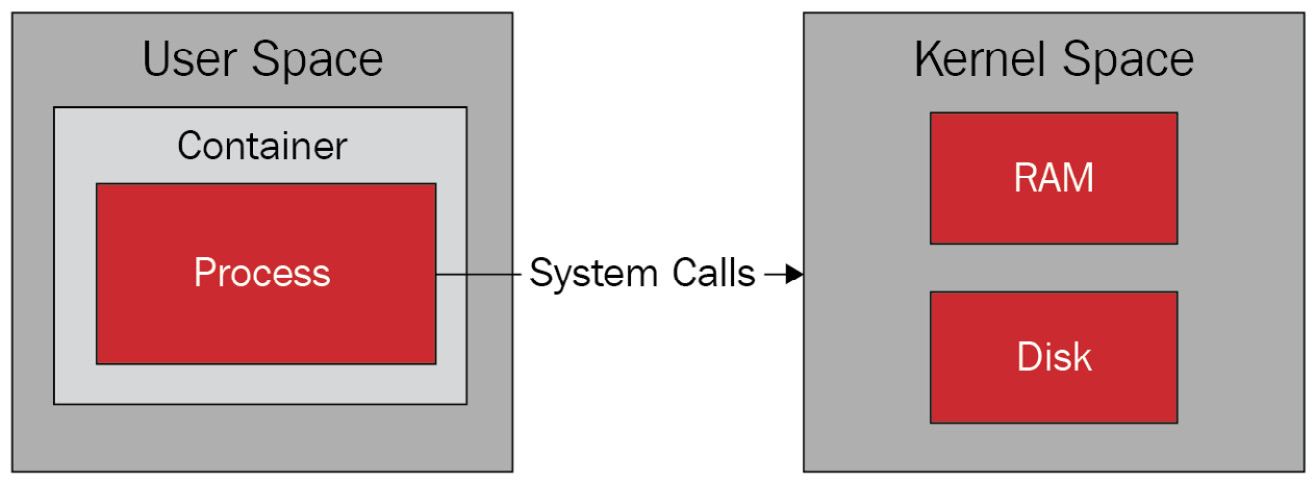
Exemple d'un appel système de l'espace utilisateur vers l'espace noyau.
Source : Podman for DevOps
Pour en savoir plus sur les appels systèmes, l'espace utilisateur et noyau.
 Contributors to Wikimedia projects
Contributors to Wikimedia projects Contributors to Wikimedia projects
Contributors to Wikimedia projects
Maintenant qu'on a vu comment fonctionne un processus, voyons voir du côté des conteneurs.
2-Qu'est-ce qu'un conteneur Docker ?
Un conteneur Docker est une instanciation d'une image qui contient le code applicatif ainsi que toutes ses dépendances et librairies qui peut être déployé dans un environnement d’exécution isolé du système hôte et vu comme un processus par ce dernier.
Tout cela est permis à travers deux fonctionnalités du noyau Linux qui sont utilisés pour isoler et gérer les ressources :
- Les cgroups (control groups ou groupes de contrôle),
- Les namespaces (espaces de noms),
L'avantage qu'offre ces deux fonctionnalités, c'est qu'aucun conflit ne peut survenir entre les applications conteneurisés car comme indiqués plus haut, les dépendances et les librairies sont inclus dans les images des conteneurs, c'est à dire qu'il n'y a aucun partage comme c'est le cas avec des applications natives.
Si vous souhaitez par exemple déployer des applications comme un serveur Web NGINX ou une base de donnée MySQL en différentes versions sur votre serveur, aucun conflit ne surviendra entre les conteneurs. C'est tout le contraire des applications qu'on installe de manière traditionnelle qui ne disposent d'aucune isolation et qui peuvent rencontrer de multiples conflits.
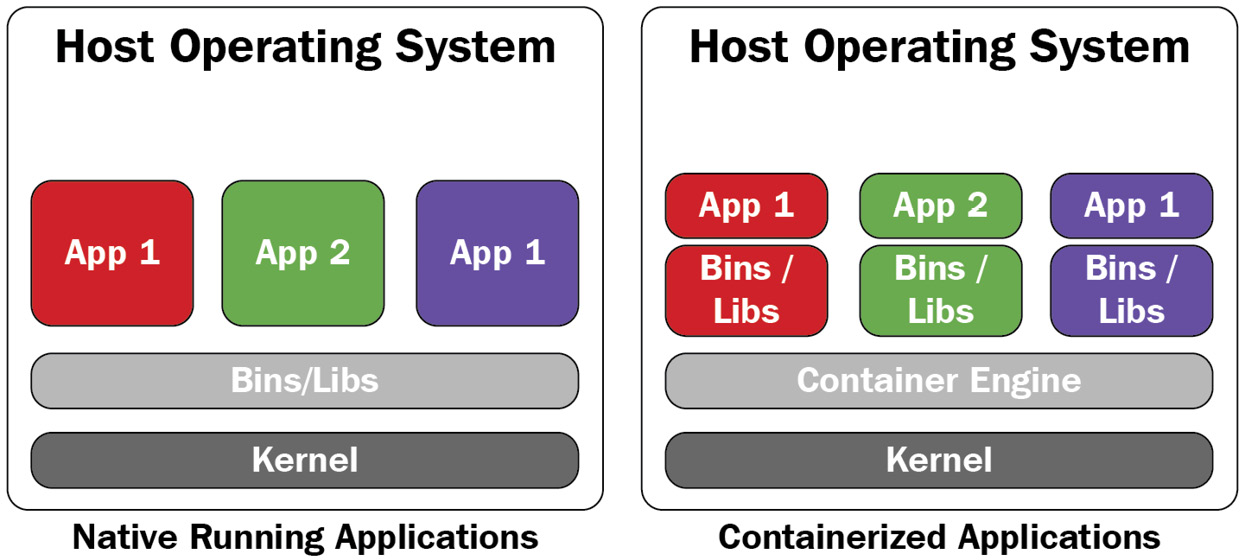
Comparatif application native vs application conteneurisée.
Source : Podman for DevOps
Les conteneurs Docker ont l'énorme avantage de fonctionner de la même manière et ce, peu importe votre infrastructure.
C'est ce qui a fait son succès depuis 2013, sa portabilité et le fait qu'il est résolu le problème du "ça marche sur mon poste".
Du côté de l'isolation, un conteneur Docker est isolé du système hôte au niveau du système de fichiers, du réseau, du processus, des UID/GID (utilisateurs/groupes) et du IPC.
3-Les deux briques de base des conteneurs
Retenez quelque chose de fondamental et je dis bien FONDAMENTAL.
Que ce soit LXC, Docker ou l'orchestrateur Kubernetes, les conteneurs ne peuvent fonctionner sans deux fonctionnalités du noyau Linux :
- Les cgroups (groupes de contrôle),
- Les namespaces (espaces de noms),
Sans ces deux fonctionnalités, point isolation et point de gestion des ressources. Plongeons en eau profondes et voyons plus en détail ce que sont ces deux fonctionnalités.

cgroups (control groups)
Pour la petite histoire, cgroups s'appelait autrefois Process Containers. Il fût lancé par Google en 2006 et a été intégré au noyau Linux 2.6.24 en janvier 2008.
Qu'est-ce que les cgroups au juste ? Les cgroups permettent de :
- Limiter et mesurer les ressources (calcul, mémoire, réseau, stockage),
- Prioriser des groupes,
- Isoler via les espaces de nom (namespaces),
Contributors to Wikimedia projectsnamespaces
Les namespaces (espaces de nom) sont une fonctionnalité du noyau Linux qui a été introduite en 2002 dans la version 2.4.19.
Ils permettent d'abstraire des ressources du système et de les faire apparaître comme uniques au processus isolé tout en évitant les conflits.
Il y a 7 types de namespaces (et donc d'isolation).
- PID : identifiant de processus,
- User : les utilisateurs et les groupes.
- UTS : nom d'hôte et de domaine,
- Network : protocoles (IPv4, IPv6), numéro de port, routage, règles de pare-feu, tout cela à travers une carte réseau virtuelle,
- IPC : inter-process communication ou communication inter-processus. Échanges et synchronisation des données entre processus.
- cgroup : gestion des ressources,
- Mount : les points de montage,
- Time : le fuseau horaire,
Pour vous donner un exemple, voici une de mes applications qui tourne sur mon serveur.
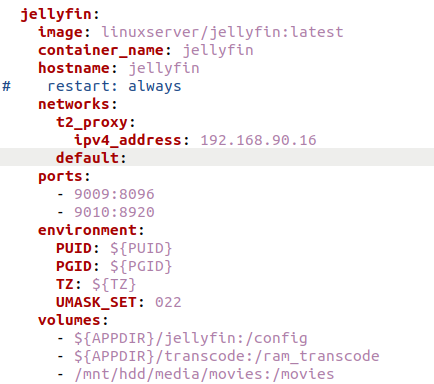
Comme vous pouvez le constater, le conteneur dispose bien de son nom d’hôte, d'un port attribué (il utilise la même adresse IP que le système hôte), d'un PUID/GUID, d'un fuseau horaire et de volumes montés à partir d'un partage local et NFS.
je le répète, sans les namespaces, point d'isolation. Le système hôte ne pourrait gérer autant d'éléments simultanément sans que cela provoque un conflit.
Contributors to Wikimedia projects
Maintenant, voyons voir la différence entre les conteneurs et les machines virtuelles.
4-Conteneurs Docker vs machines virtuelles
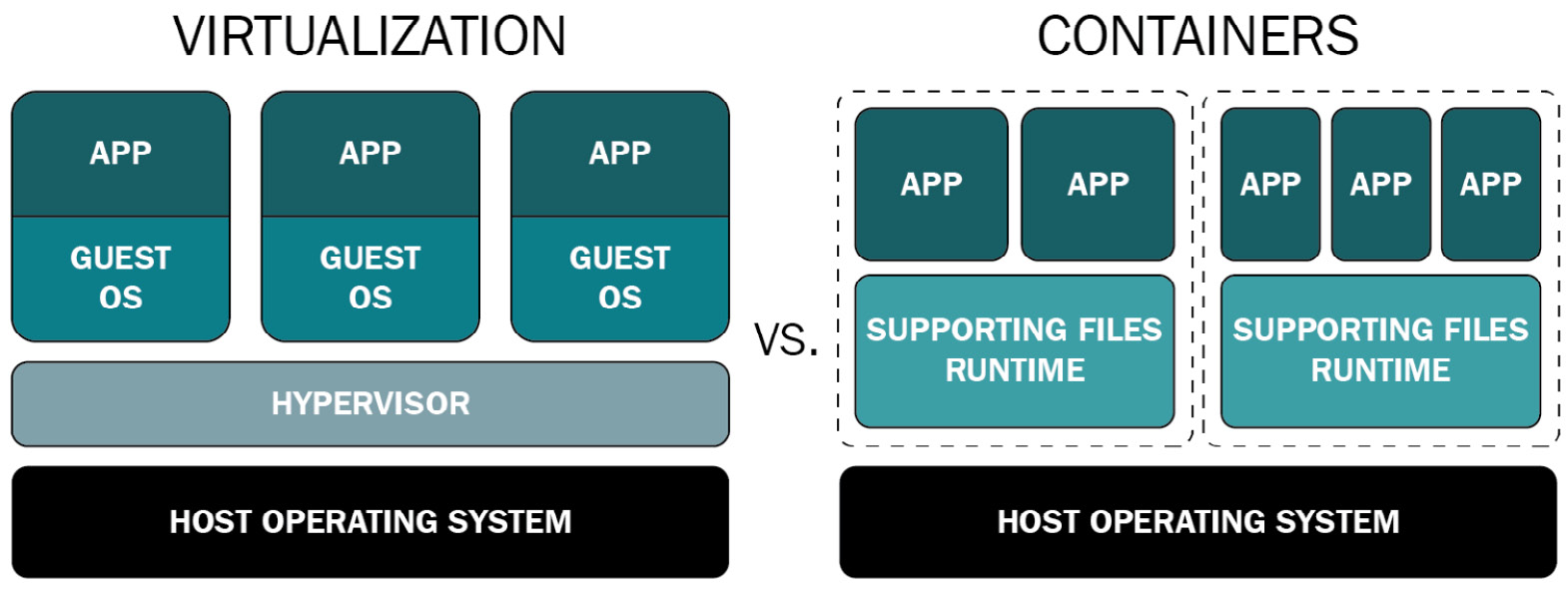
À défaut de pouvoir brosser un tableau détaillé des différences ntre les conteneurs et les machines virtuelles, nous allons en voir trois en particulier :
- Les appels systèmes,
- L'isolation,
- La consommation en ressources,
Les appels systèmes
Une machine virtuelle est une représentation logique d'une machine physique avec un système d'exploitation invité (guest OS) qui dispose de son propre noyau.
Pour que l'application dans une machine virtuelle puisse accéder aux ressources du matériel, elle effectue des appels systèmes au noyau du système invité qui lui même fera de même avec l'hyperviseur, module du noyau du système hôte du serveur. Pour schématiser :
application => system calls => guest OS kernel => hypervisor
Un conteneur partage le noyau avec l'ensemble des autres conteneurs. Pour accéder aux ressources du système hôte, le conteneur fait appel à l'une des fonctionnalité du noyau Linux, les cgroups et va effectuer des appels systèmes de l'espace utilisateur vers l'espace noyau.
Autrement dis, le conteneur n'a pas besoin d’intermédiaire pour communiqué avec le noyau et accéder aux ressources du matériel.
L'isolation
Une machine virtuelle a besoin d'un hyperviseur (Xen, KVM, Hyper-V, ESXi), une couche d'abstraction qui permet d'accéder aux ressources de la machine physique tandis qu'un conteneur est un processus qui utilise les espaces de noms (namespaces), une fonctionnalité du noyau Linux pour être isolé du système hôte.
Il faut savoir qu'une machine virtuelle ne vois que l'hyperviseur, elle ne vois pas le matériel sous-jacent. C'est ce qui permet à plusieurs systèmes d'exploitation (Windows, Linux, BSD, Solaris) de cohabiter les uns avec les autres. au contraire des conteneurs Docker qui ont besoin de tourner sur un système Linux car dépendant du noyau du système hôte.
Les machines virtuelles bénéficient d'une meilleure isolation et d'une meilleure sécurité que les conteneurs mais on a vu avec les récentes failles de sécurité chez Intel comme Meltdown et Spectre (failles matérielles, plus difficile à corriger) qu'il est possible d'exploiter des vulnérabilités liés au processeur pour accéder à une machine virtuelle.
C'est pour cette raison que des recherches ont été effectués pour trouver un compromis entre les deux mondes.
Le dilemme était le suivant : comment coupler les avantages des conteneurs (rapidité d’exécution, taille des images, portabilité) avec ceux des machines virtuelles (noyau dédié, faire tourner différentes systèmes d'exploitations simultanément) ?
La réponse a été trouvé avec deux solutions Kata-containers et Firecracker de AWS, des micro-machines virtuelles sous KVM avec un temps de démarrage réduit et une charge CPU allégé.
Lisez, c'est vraiment très très intéressant.

 Wonderfall
Wonderfall
Attention, cela veut pas dire que les conteneurs sont des passoires, loin de là. Juste que le travail de sécurisation est beaucoup plus long à mettre en place.
Voici 3 liens au sujet de la sécurisation des conteneurs pour ceux que ça intéresse.
 Aqua Security
Aqua Security

la consommation en ressources
Étant un processus, une instanciation d'une image, un conteneur consomme à peine plus qu'une application en version standard.
Une machine virtuelle nécessite de disposer des instructions de virtualisation (Intel VT-x/AMD V), ce qu'on appelle "HAV" (Hardware Assisted Virtualization ou virtualisation assisté par le matériel). Cela facilite la tâche de l'hyperviseur dans l'accès aux ressources de la machine physique.
Mais étant la représentation logique d'une machine physique, elle nécessite l'émulation des différents périphériques qui la compose, ce qui génère une forte charge CPU.
De plus, tout dépend de quel type de virtualisation on parle.
En virtualisation complète (translation binaire), la charge CPU est non négligeable tandis qu'en para-virtualisation, le charge CPU est allégé du fait d'un accès privilégié aux ressources (le système est conscient d'être virtualisé).
Si on devait résumer :
- Les conteneurs n'ont pas besoin d'intermédiaire, sont plus légères, plus rapides à démarrés (en quelques millisecondes) et isolés du système hôte.
- Les machines virtuelles sont plus lourdes, plus longues à démarrés, nécessitent une émulation des différents périphériques, disposent de leur propre noyau, d'une meilleure isolation, d'une meilleure sécurité que les conteneurs.
Ce n'est pas anodin si les conteneurs sont majoritairement exécutés à partir de machines virtuelles et non sur du bare metal.
Les deux se complètent parfaitement et ne sont pas en concurrence. Tout juste peut-on constater que l’ère des application monolithiques déployé dans des machines virtuelles est révolu au profit de l'architecture microservices et de la méthodologie DevOps.
Sources :
 Alessandro Arrichiello
Alessandro Arrichiello Miguel Pérez Colino
Miguel Pérez Colino