Une brève histoire des conteneurs
Une brève histoire des conteneurs.

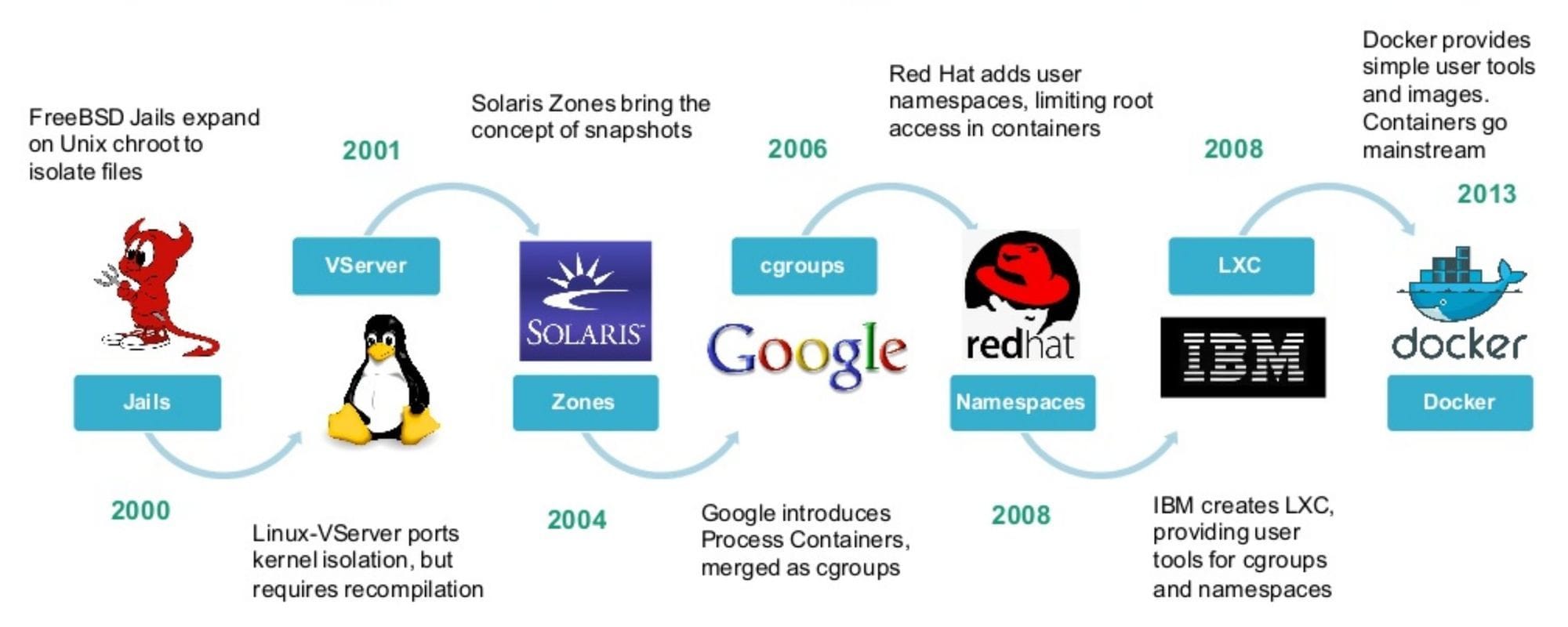
Au sommaire :
- 1-Introduction
- 2-chroot (1979)
- 3-Les prisons BSD Jails (2000)
- 4-Linux VServer (2001)
- 5-Solaris Zone (2004)
- 6-Open VZ (2005)
- 7-Process containers (2006)
- 8-LXC (2008)
- 9-Warden (2011)
- 10-LMTCFY (2013)
- 11-Docker (2013)
- 12-L’après Docker
- 13-Les runtimes
- 14-Les runtimes de bas niveau
- 15-Les runtimes de haut niveau
- 16-Conteneurs x Machines virtuelles
1-Introduction
Pour ceux qui ont découvert les conteneurs à partir de Docker ou LXC comme moi, sachez qu'il y a une règle en informatique et dans les technologies en général qui est que que toute nouveauté en apparence est en fait le fruit de longues expérimentations et d'échecs successifs avant qu'elle n'arrive à maturité.

C'est le cas de Docker et de Kubernetes. Ces dernier n'ont pas inventé les concepts de conteneur et d'orchestrateur mais on popularisé ces concepts et ont apportés des innovations de taille qui ont transformé le marché et sont depuis devenus des standards de l'industrie.
Comme on dis : "in the right place at the right time" (au bon endroit au bon moment).
L'origine des conteneurs remonte à la fin des années 70 avec la naissance de chroot (change root).
2-chroot (1979)
L'année 1979, c'est David Bowie qui sort le dernier opus de sa trilogie berlinoise "Lodger", c'est la vague "new-wave" qui deferle en Occident, la stagflation qui bat son plein aux Etats-Unis et c'est aussi l'année de naissance des conteneurs avec chroot sur Unix v7, le système conçu par Ken Thompson et Dennis Ritchie dans les laboratoires de Bell Labs.
Le concept est simple. Lors de la création d'un nouveau processus, ce dernier est isolé du système hôte, dispose de sa propre arborescence et des règles peuvent désormais s'appliquer comme interdire tout accès aux fichiers et répertoires du système hôte par exemple (c'est le seul type d'isolation).
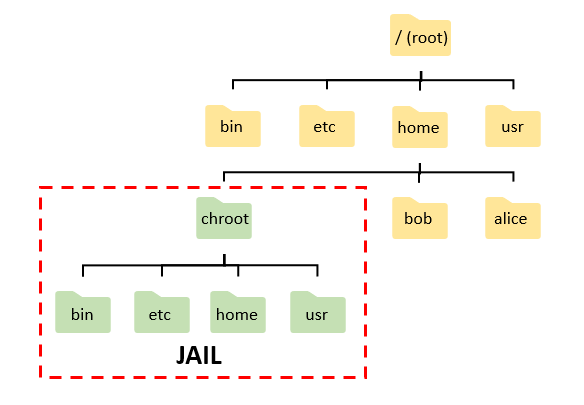
Ce n'est pas encore la panacée en terme de sécurité mais c'est officiellement la première tentative d'isolation d'un processus. Il faudra attendre 21 ans plus tard pour que l'idée soit reprise du côté de FreeBSD avec les BSD Jails.
Note : on verra par la suite avec les "namespaces" sous Linux que l'isolation ne concernera plus uniquement le système de fichiers mais d'autres éléments.
3-Les prisons BSD Jails (2000)
L'idée de chroot a fait son chemin et sera sera introduit en 1982 sur FreeBSD.
21 ans plus tards, apparaissent les les BSD Jails. Les conteneurs vont faire un bond en avant considérable.
Les BSD Jails disposent toujours de leur propre arborescence mais aussi (c'est une première) de leur processus, de comptes utilisateurs, d'une adresse IP, de leur propre système d'exploitation et utilisent le noyau du système hôte.
L'utilisateur peut également mettre en place des règles de sécurité spécifiques à chaque BSD Jail.
L'avantage, c'est que si un hacker s'introduit dans une application BSD Jails, il ne pourra pas remonter jusqu'au système hôte.
Cela vous semble familier ? C'est ni plus, ni moins que du LXC avant l'heure.
4-Linux VServer (2001)
C'est exactement le même concept que BSD Jail mais dans l'univers Linux. Il n'est plus maintenu depuis 2006 (date du dernier patch).
À noter qu'il n'a jamais été intégré au noyau Linux, ce dernier dois donc être recompilé au préalable (comme OpenVZ d'ailleurs).
5-Solaris Zone (2004)
Idem que pour Linux VServer, c'est le même concept que les BSD Jails mais pour les systèmes Solaris comme OpenIndiana, SmartOS, Tribblix et OmniOS et Oracle Solaris 11 qui fonctionne sur les architectures x86 et SPARC.
Solaris introduit la notion de zones.
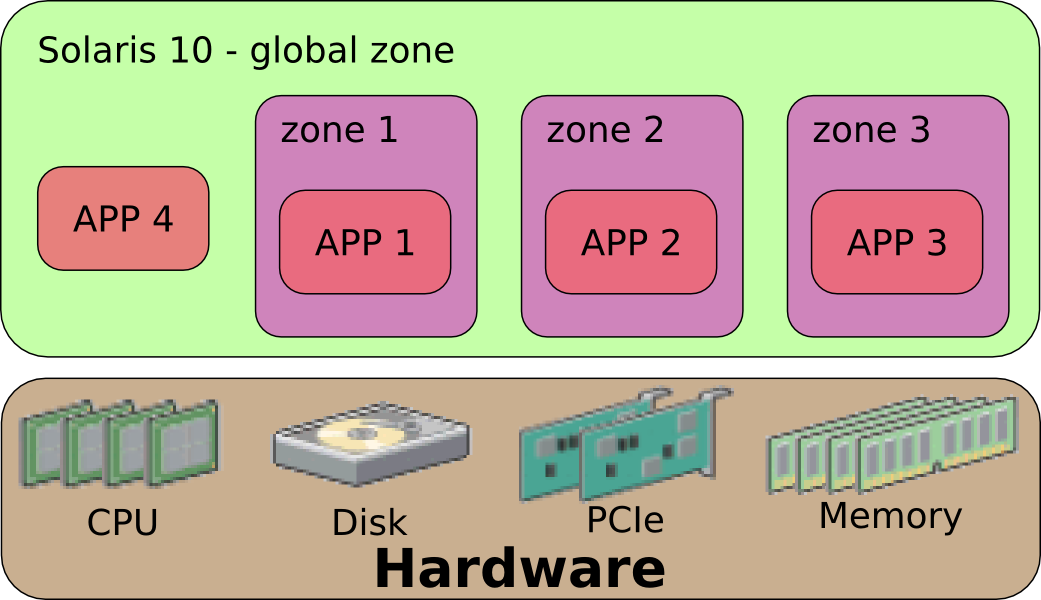
Chaque zone dispose de son accès aux interfaces réseau virtuelles ou physiques, de son pool d'adressage IP et du stockage qui lui est attribué. Chaque système hôte à une limite maximale de 8191 zones.
Solaris innove également avec deux autres concepts :
- Les "Sparse Zones" sont des zones de partage de fichiers en commun entre conteneurs, idéal pour économiser de l'espace disque,
- Les "Whole Root Zones" sont des zones plus restrictives où le partage de fichiers entre conteneurs est interdite au profit d'une meilleure isolation mais aussi d'une plus grande consommation de l'espace disque,
Enfin, il est possible de faire des instantanés (snapshots) et des clones des conteneurs grâce au système de fichiers ZFS de chez Sun Microsystem.
6-Open VZ (2005)
Open VZ ((Open Virtuzzo) est une méthode de virtualisation au niveau du système d'exploitation qui permet de créer plusieurs conteneurs isolés les uns des autres et qui dépendent du noyau Linux.
Comme Linux VServer et contrairement à LXC, il n'est pas intégré au noyau Linux et n'évolue donc pas en parallèle avec lui. C'est pour cette raison précise que depuis la version 4.0, Proxmox VE n’intègre plus OpenVZ et qu'il a été remplacé par LXC.
Linux VServer, Solaris Zones, OpenVZ, les cadavres s'accumule....

7-Process containers (2006)
Process Containers fût lancé par Google en 2006, société qui comme nous le verront dans les prochains articles a une très grande expérience dans le domaine des conteneurs.

Il est plus connu aujourd'hui sous le nom de cgroups et a été intégré au noyau Linux 2.6.24 en janvier 2008.
Qu'est-ce que les cgroups au juste ? Les cgroups permettent de
- Limiter et mesurer les ressources.
- Prioriser certains groupes.
- Isoler via les espaces de nom (namespaces).
Pour les habitués de Proxmox VE, lorsque vous créez un conteneur LXC, c'est lui qui gère l'attribution des ressources en mémoire, en temps processeur, en stockage et en réseau au conteneur.
8-LXC (2008)
Lancé en août 2008, LXC (Linux Containers) tout comme OpenVZ est une méthode de virtualisation au niveau du système d'exploitation qui permet de créer plusieurs conteneurs isolés les uns des autres et qui dépendent du noyau Linux.
Intégré à la solution Proxmox VE depuis la version 4.0, LXC remplace OpenVZ. La raison est que LXC ne nécessite aucune modification du noyau contrairement à OpenVZ, ce qui fait qu'il évolue en parallèle avec lui à chaque mise à jour.
Pour la petite histoire, LXC était le runtime (environnement d’exécution) par défaut de Docker avant d'être remplacé par libcontainer ainsi que de Warden (que nous verront plus bas).
LXC fonctionne sur le principe des cgroups (control groups ou groupes de contrôle) et namespaces (espaces de nom) qui sont des fonctionnalités du noyau Linux.
- Cgroups : permet de limiter et mesurer les ressources, prioriser certains groupes et isoler via les espaces de nom (namespaces).
- Namespaces : conçu par les équipes de Red Hat, c'est une méthode d'isolation qu'on retrouve dans Kubernetes qui permet d'isoler un groupe de processus d'un autre groupe de processus en créant des partitions des ressources.
Et c'est à partir de LXC qu'on entendra parler de conteneurs privilégiés et non privilégiés. L'idée est simple :
- Privilégié : le conteneur à aucune restriction (montages de partage NFS/SMB, gpu passthrough, pci passthrough) un attaquant pourra remonter à la racine du système hôte. Plus de liberté mais plus de responsabilité.
- Non privilégié : le conteneur est verrouillé de tout part et l'attaquant ne pourra pas remonter à la racine du système hôte.
Les avantages des conteneurs LXC sont nombreux :
- Leur rapidité d’exécution,
- La faible taille sur le disque,
- Leur impact modéré en performance qui permet de réduire le nombre de machines virtuelles par serveur et d’exécuter plus de conteneurs applicatifs,
- Pouvoir exécuter différentes distributions (Debian, Ubuntu, Centos, Rocky Linux, Alpine, Arch etc),
Les inconvénients :
- Aucun support des migrations en direct (il faut passer par LXD, une surcouche de LXC développé par Canonical),
- Dépendant du noyau du système hôte (comme tout les conteneurs en général),
LXC avait tout pour réussir et rendre populaire l'usage des conteneurs mais ce ne sera pas suffisant pour qu'il soit adopté en tant que standard de l'industrie.
9-Warden (2011)
Warden est une technologie de conteneurisation utilisé sur Cloud Foundry, un PAAS (Platform as a Service).
Utilisant au départ LXC, il utilisera par la suite son propre runtime. Il fonctionne comme un processus (daemon), utilise également les "cgroups", les "namespaces" et apporte avec lui (c'est la grande nouveauté) une API programmable.
Pour la petite histoire, Cloud Foundry appartenait à VMware (2009) puis à Pivotal (2013) pour ensuite devenir un projet indépendant hébergé par la Linux Foundation.
Warden n'est plus mis à jour depuis 2015.
10-LMTCFY (2013)
Lancé en 2013 par Google, LMTCFY (Let Me Contain That For You) est basé sur la fonctionnalité "cgroups" de Linux.
Sa grande particularité est de permettre de créer des sous-conteneurs dans les conteneurs, une option qu'on ne retrouvera jamais sur Docker.
Le projet fut stoppé en 2015 depuis que Google contribue à libcontainer (runtime par défaut de Docker) hébergé par l'Open Container Foundation.
11-Docker (2013)
Lancée en mars 2013 par l'équipe de Solomon Hykes, un franco-américain passé par l'école Epitech, Docker va démocratiser l'usage des conteneurs auprès des développeurs et des administrateurs. L'adoption est massive, c'est l'explosion!!!!!

Et c'est à partir de 2013 qu'on rentre dans l’ère des conteneurs, c'est l'âge d'or, les golden years!!!!!!

Si les conteneurs sont devenus aussi populaires, tant du côté des développeurs que des administrateurs en passant par l'industrie du cloud. c'est en partie grâce à lui.
Que ce soit les fournisseurs cloud, les entreprises privés voir même les particuliers à travers l’auto-hébergement, les conteneurs sont devenus la technologie dominante de ces dernières années.
Certaines caractéristique de Docker sont devenu des standards de l’industrie (comme le format des images et le runtime) à travers les spécifications de l’OCI (Open Container Initiative).
Pourtant, l’idée des conteneurs n’est pas si neuve et date de la fin des années 70 avec chroot sur les systèmes Unix comme on a pu le voir dans la partie 1 de mon article "Une brève histoire des conteneurs (1979-2013)".

Mais pourquoi Docker a réussit là ou d'autres ont échoués ?
Tout simplement car il était là au bon moment et qu'il a apporté des solutions à des problématiques de longue date.
"in the right place at the right time"
Voici une interview de Soomon Hykes, fondateur de la société Docker, Inc qui explique en quelques minutes sa folle ascension.
11.1 - Les fonctionnalités clés de Docker
Les images
Les images contiennent le code applicatif, les libraires et les dépendances, le tout organisés sous formes de couches et fusionnés à travers le OverlayFS, un système de fichiers natif de Linux.
Les spécifications des images Docker sont désormais devenu un standard de l'OCI (Open Container Initiative). Elles doivent nécessairement respecter les éléments suivants :
- La liste des couches.
- La date de création.
- Le système d'exploitation.
- L'architecture du processeur (ARM, AMD64).
- Paramètres de configuration.
Immuabilité
Le coup de génie de Docker, c'est d'avoir fait des applications conteneurisés des instances immuables et éphémères.
Vu que rien de persistent est stocké dans les conteneurs (tout doit-être externalisé), ils peuvent être détruit et déployés à volonté.
Avec Docker (et surtout avec Kubernetes), c'est la généralisation des pipelines CI/CD, de l'architecture micro-services et la culture DevOps prend enfin son envol.
Les dépôts (registry)
Les "Registry" sont des dépôt publics ou privés où les utilisateurs peuvent poussés et téléchargés des images d'applications ainsi que les mettre à disposition du public ou de leur organisation.
Quelqu'un qui souhaite par exemple téléchargé et déployé la dernière version du serveur web NGINX ou Apache aura juste à taper les commandes suivantes.
docker run nginx
docker run apacheCe sont des commandes simples mais derrière, il s'en passe des choses :
- Docker va vérifier si l'image existe dans le cache en local.
- Si non, il va chercher dans la liste des dépôts par défaut.
- Il télécharge l'image.
- Et déploie le conteneur.
Portabilité
Peu importe la distribution utilisé, client ou serveur, on-premise ou cloud public, à partir du moment où Docker est installé dans le système, le conteneur trouvera le même environnement d’exécution (runtime) pour pouvoir fonctionner convenablement.
Il résous ce qu'on appelle en anglais le "it works on my machine", qu'une application fonctionne sur la machine A mais pas sur la machine B.

Abordons désormais l'après Docker car l'histoire ne s'arrête pas là.
12-L’après Docker
À partir du moment où les conteneurs sont de plus en plus utilisés par l'industrie, il a fallu harmoniser ça, créer des standards et tout un écosystème.
2015 est une année clé dans l'adoption des conteneurs par l'industrie avec la fondation de deux sous entités de la Linux Foundation :

- La CNCF (Cloud Native Computing Foundation) qui participe à la promotion de l'écosystème des conteneurs.
- L'OCI qui est une structure de gouvernance ouverte autour de l'écosystème des conteneurs. Elle fixe notamment les spécifications liés aux images et aux runtimes.

13-Les runtimes
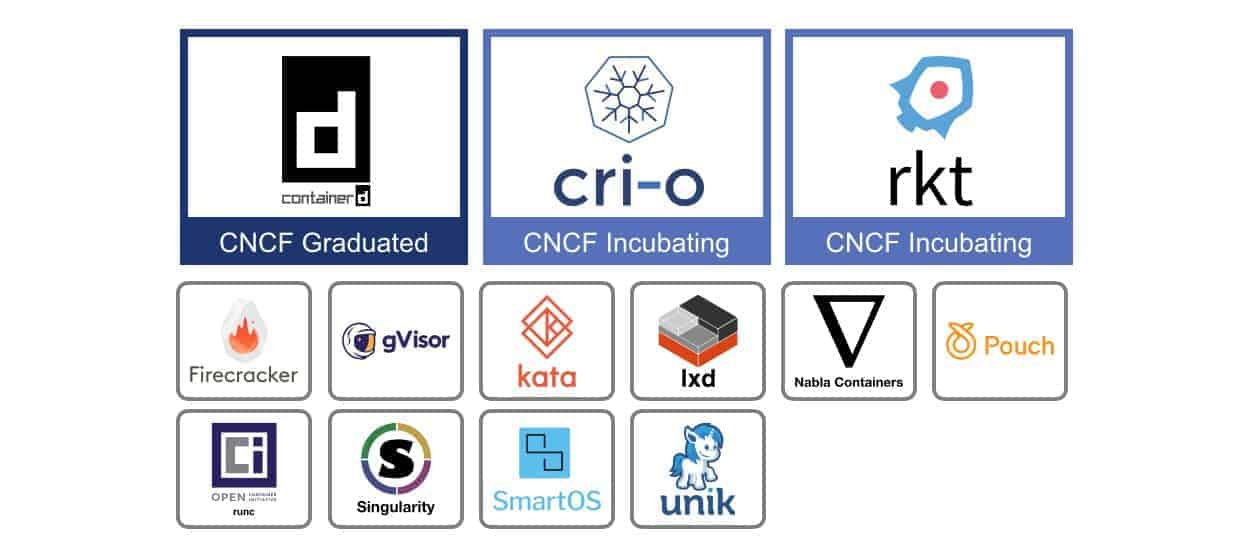
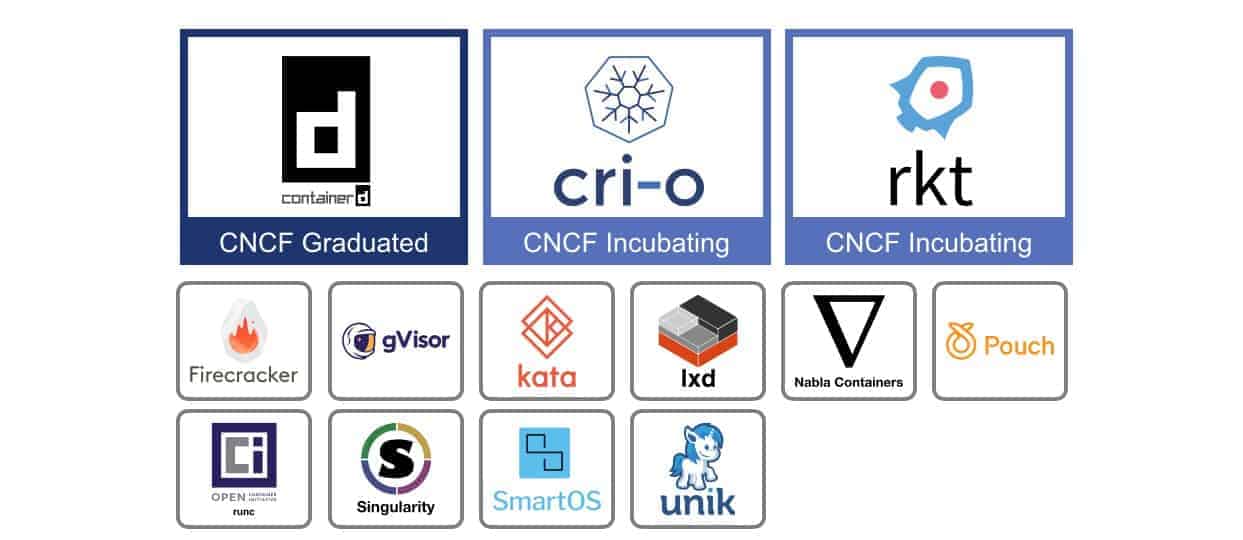
Parlons désormais des runtime. Comme vous pouvez le voir dans l'image ci-dessus, il y en a une belle pelleté.
Pour éviter les répétitions dans le texte :
Ils sont tous soutenus par la CNCF et ils respectent tous la spécification OCI dont notamment :
- OCI Runtime Specification.
- OCI Image Specification.
 opencontainersopencontainers
opencontainersopencontainersÀ noter qu'il ne faut plus parler d'images Docker mais d'images OCI et qu'il existe une multitude de runtimes conforme à la spécification OCI.
Profitez-en pour vous faire une idée sur l'ensemble des projets soutenus par la CNCF, ça donne le tournis.


14-Les runtimes de bas niveau
runc (2015)

Développé en langage Gp, runc (run container) est un runtime de bas niveau permettant de créer et d'exécuter des conteneurs.
Issus du runtime libcontainer offert par Docker à l'OCI, il est le plus populaire de l'industrie en étant utilisé par containerd (utilisé Docker) et CRI-O (le runtime le plus utilisé sur Kubernetes).
opencontainerscrun (2019)

Développé en langage C, crun est l'alternative à runc conçu par Red Hat.
Idem que pour runc, crun est un runtime de bas niveau permettant de créer et d'exécuter des conteneurs.
Il est loin devant runc mais il est le runtime par défaut de Podman, le successeur de rkt.
Il est plus léger et consomme moins de ressources mémoires que runc.

Note : On peux citer également LXC comme runtime de bas niveau, déjà cité dans la partie 1.
Voyons voir du côté des runtimes de haut niveau.
15-Les runtimes de haut niveau
Les runtimes de haut niveau (High-level container runtime) à part rkt utilisent runc ou crun et sont accompagnés d'une API.
rkt (2014)

rkt, à prononcer “rock-it" était un runtime concurrent à Docker conçu par les équipes de CoreOS.
En 2017, il devient un projet soutenu par la CNCF.
rkt dispose de deux particularités très intéressantes :
- Il est "daemonless", aucun processus ne tourne en tâche de fond.
- Il est "rootless", c'est à dire qu'il peut-être utilisé avec des comptes standards.
Pour ceux qui ont de la bouteille, c'est deux reproches récurrent fait à Docker, le fait qu'il nécessite un daemon et des accès root.
Que se passerait-t-il si par exemple le daemon de Docker était compromis ?

Cela veut dire qu'au lieu d'avoir un daemon qui gère le cycle de vie des conteneurs (une certaine forme de centralisation), chaque conteneur aurait son propre daemon.
Pour la petite histoire, la société CoreOS sera racheté par Red Hat pour 250 millions de dollars qui obtiendra en plus du runtime rkt, la distribution immuable CoreOS et Tektonic, une solution sous Kubernetes et rkt.
- rkt disparaîtra mais les idées essentielles seront reprises avec Podman, Buildah et Skopéo,
- La distribution immuable CoreOS fusionnera avec Red Hat Atomic, ce qui donnera naissance à Fedora CoreOS/Red Hat CoreOS (RHCOS).
- Fedora CoreOS/RHCOS seront la base de OKD/Red Hat OpenShift.
Tout est recyclé en informatique.


 Dominique Filippone
Dominique Filippone
containerd (2015)

containerd est le runtime de Docker et de CRI-O.
Pour schématiser le fonctionnement de containerd, lorsque vous utilisez le CLI de Docker, vous communiquez avec le daemon et ce dernier va transmettre les informations à containerd (haut niveau) qui va ensuite le transmettre à runc (bas niveau) et enfin exécuter votre demande.

Source : Podman for DevOps
Pour la petite histoire, LXC était le premier runtime par défaut de Docker. Il sera remplacé un an plus tard par libcontainer, un runtime écrit en langage Go (tout comme Docker) conçu par les équipes de Docker, Inc.
Entre temps, le centre de gravité bascule de Docker vers Kubernetes, surtout à partir de 2017 lorsque ce dernier gagne la guerre des orchestrateurs.
Une standardisation des spécifications était en cours au sein de l'OCI, notamment en ce qui concerne le format des images et la manière d’exécuter les conteneurs avec le runtime.
libcontainer sera offert à l'OCI, ce qui donnera naissance au projet de runtime de bas niveau runc qui sera également offert à l'OCI.
containerd dissocie la gestion des conteneurs du daemon Docker et permet d'accéder aux ressources bas niveau sans avoir besoin de ce dernier.
Notez également que Kubernetes déprécie docker-shim à partir de la version 1.24.
Depuis le 28 février 2019, il est un projet dis "graduated" de la CNCF.

 Tremplin Numérique
Tremplin Numérique



LXD (2017)

LXD (pour Linux daemon) est une surcouche à LXC conçu et promu par les équipes de Canonical.
Il apporte entre autre la migration en direct, chose impossible à effectuer avec LXC (le conteneur doit être arrêté, migré puis de nouveau allumé).

Podman (2017)

Développé par Red Hat, Podman (contraction de POD MANager) permet d’exécuter des conteneurs et a été conçu dans l'objectif d'être l'alternative de référence à Docker.
Il utilise crun comme runtime de bas niveau et la paire Buildah/Skopeo pour la construction et le transfert d'images.
Podman, Builda et Skopéo reprennent la philosophie de rkt :
- Il sont "daemonless", aucun processus ne tourne en tâche de fond.
- Il sont "rootless", c'est à dire qu'ils peuvent-être utilisé avec des comptes standards.
Podman intègre également le concept de pods (groupe de un ou plusieurs conteneurs) et permet de génèrer des fichiers unit systemd ainsi que des manifestes kubernetes à partir de pods ou conteneurs existants.
Il est de plus en plus utilisé en dehors de l'écosystème Red Hat.
Il est également inclus par défaut dans OpenStack à travers TripleO.
Il fera l'objet d'une série d'articles prochainement.

CRI-O (2017)

Kubernetes a mis en place le plugin CRI (pour Container Runtime Interface) qui permet de prendre en compte d'autres runtimes que celui de Docker ou celui CoreOS (rkt).
Conçu par Red Hat, CRI-O est l'un des runtimes le plus populaire sous Kubernetes avec containerd et celui utilisé par défaut d’Openshift, de SUSE CaaS platform ainsi que openSUSE Kubic.
Il fonctionne avec runC mais également avec crun, Kata Containers


Gvisor (2018)

Gvisor est une application écrite en langage Go conçu par Google qui a la particularité d’exécuter des conteneurs dans un environnement Linux en bac à sable (sandbox) sans passé par la virtualisation.
C'est à dire que l'application ne vois pas le noyau du système hôte mais celui de gVisor, ce qui limite considérablement la surface d'attaque.
Pourquoi je dis ça ? Malgré tout les avantages des conteneurs, n'oubliez pas qu'ils sont dépendant du noyau du système hôte. Il suffit d'une vulnérabilité parmi vos conteneurs pour qu'un attaquant puisse s'échapper et accéder au système hôte.
il remplace le runtime de bas niveau runc et la seule limitation de Gvisor est de ne pas pouvoir exécuter tout type d'applications (il ne gère pas tout les appels systèmes).
Il est utilisé en production chez Google dans des solutions comme Google App Engine, Google Cloud Functions et Google Cloud Run.
Ce n'est donc pas un VMM comme Kata-containers, Firecracker ou RunX (qu'on verra plus bas) mais ils ont le même objectif, améliorer l'isolation des conteneurs.



16-Conteneurs x Machines virtuelles
Depuis la fin des années 2010 (et bien avant), des recherches ont été menés pour améliorer la sécurité des conteneurs.
Imaginez. La rapidité d’exécution, la taille réduite et la faible consommation en ressource des conteneurs couplé à l'isolation et la sécurité des machines virtuelles.
Différents projets ont vu le jour.
Kata-containers (2017)

Hébergé par l'Open Infrastructure Foundation (ex fondation OpenStack), Kata-containers est la fusion de deux projets :
- Clear Containers d'Intel
- runV de Hyper.sh
Kata-containers permet d'exécuter des micro-machines virtuelles (MicroVMs) avec des hyperviseurs comme Firecracker, NEMU, Cloud Hypervisor (basés sur QEMU/KVM) mais s'est ouvert depuis à d'autres comme ACRN.
kata-containers


Firecracker (2018)
Conçu par AWS et écrit en langage Rust, Firecracker permet également de créer des micro-machines virtuelles (MicroVMs)
Il est spécialement calibré pour le serverless et supporté par le projet kata-containers.
Pour la petite histoire, j'ai découvert Firecracker à travers ce tutoriel de deep75 au sujet de Weave Ignite.



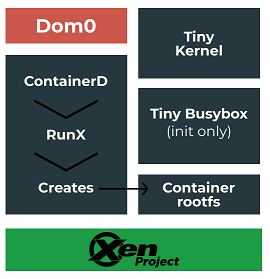
RunX (2020)
RunX est un ensemble de scripts qui a pour but de remplacer runc (tout en utilisant containerd) et qui exécute des conteneurs comme des machines virtuelles.
Contrairement à Firecracker et Kata-containers, il se base sur l'hyperviseur Xen.

C'est la fin de cette brève histoire des conteneurs. De nombreux projets tournent autour de la CNCF mais beaucoup sont encore en incubation, d'autres sont carrément plus mis à jour et j'ai donc citer les projets les plus populaires.
 Contributeurs aux projets Wikimedia
Contributeurs aux projets Wikimedia Contributeurs aux projets WikimediaContributeurs aux projets Wikimedia
Contributeurs aux projets WikimediaContributeurs aux projets Wikimedia Contributeurs aux projets Wikimedia
Contributeurs aux projets Wikimedia Contributors to Wikimedia projects
Contributors to Wikimedia projects Contributeurs aux projets Wikimedia
Contributeurs aux projets Wikimedia Contributors to Wikimedia projectsContributeurs aux projets Wikimediacloudfoundry-atticContributors to Wikimedia projects
Contributors to Wikimedia projectsContributeurs aux projets Wikimediacloudfoundry-atticContributors to Wikimedia projects Contributors to Wikimedia projectsContributeurs aux projets Wikimedia
Contributors to Wikimedia projectsContributeurs aux projets Wikimedia
 Rani Osnat
Rani Osnat Contributeurs aux projets Wikimedia
Contributeurs aux projets Wikimedia



 Daniel J Walsh
Daniel J Walsh
 Wonderfall
Wonderfall
 Alessandro Arrichiello
Alessandro Arrichiello